传统嵌入+线性分类器忽略次序,只捕获词义聚合,不能处理复杂任务(文本生成,问答)->用RNN
RNN:循环神经网络
可顺序处理(逐词输入网络,每次更新内部状态),可状态传递(状态与下词一起决定新状态,保留序列信息);可用章台传递建模词序->捕捉上下文依赖
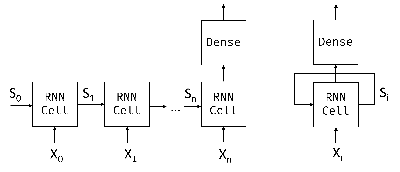
RNN工作机制:
输入序列:X0...Xn(次序列)
结构L序列快链(块处理(Xi,Si)-> 输出Si+1) + 权重共享(所有块共享参数,端对端训练)
状态传递:初始状态S0(0向量),每个步骤更新状态 + 捕获序列依赖(如not影响后续状态)
输出分类:最终状态Sn (输出Xn),输入到线性分类器
循环表示:单块网络有反馈回路(状态回传到输入)
加载新闻数据集:
import torchimport torchtext
from torchnlp import *train_dataset, test_dataset, classes, vocab = load_dataset()
vocab_size = len(vocab)
RNN单元:输入(当前词嵌入向量 + 前一步状态向量 -> 线性变换 -> 新状态向量)
用PyTorch实现RNN分类器:RNNCell(单步) 或 RNN层(序列处理)
模型架构有3个部分:嵌入层(词索引转成低维稠密向量 = 降维),RNN层(逐词处理嵌入向量 + 更新状态),分类层(最终状态输入线性层分类)
class RNNClassifier(torch.nn.Module):
def __init__(self, vocab_size, embed_dim, hidden_dim, num_class):
super().__init__()
self.hidden_dim = hidden_dim
self.embedding = torch.nn.Embedding(vocab_size, embed_dim)
self.rnn = torch.nn.RNN(embed_dim,hidden_dim,batch_first=True)
self.fc = torch.nn.Linear(hidden_dim, num_class)
def forward(self, x):
batch_size = x.size(0)
x = self.embedding(x)
x,h = self.rnn(x)
return self.fc(x.mean(dim=1))
嵌入层优化:默认用未训练的嵌入层(简单初始化),可以替换成预训练嵌入(Word2Vec,GloVe)
代码调整:加载预训练嵌入矩阵->初始化嵌入层权重,冻结/微调嵌入层参数
RNN训练:数据加载 - RNN层输出 - 分类;可能会有梯度问题,可以用梯度裁剪nn.utils.clip_grad_norm_优化,用LSTM/GRU替代基础RNN来优化(缓解长程依赖问题),可以用预训练嵌入层减少训练时间
数据加载:用填充后的批次数据(等长序列,填充短序列)
RNN层输出(x = 时间步输出序列,h=最终隐藏状态 -- 用来分类)
分类:h输入到线性分类器
梯度问题:RNN展开后层数多 -> 很难反向传播 == 梯度消失/爆炸
解决:用小学习率,扩数据集,用GPU
代码:
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=16, collate_fn=padify, shuffle=True)
net = RNNClassifier(vocab_size,64,32,len(classes)).to(device)
train_epoch(net,train_loader, lr=0.001)
过程:略
LSTM/GRU:传统RNN会梯度消失,可以引入门控机制管理状态
LSTM长短期记忆:遗忘门,输入门,输出门 + 细胞状态(长期记忆)
GRU门控循环单元 = 简化版LSTM:合并细胞状态,隐藏状态,减少参数

双状态传递:细胞状态c(长期记忆,线性传递,受门控调节) + 隐藏状态h(短期记忆,输出和门控计算)
门控结构:(sigmoid激活,输出0-1掩码),遗忘门(输入ht-1和xt -> 细胞状态ct-1保留/遗忘的部分) + 输出门(ht-1和xt -> 控制新信息加入);细胞状态更新ct,输入门(ht-1和xt -> 控制ct输出到ht部分)
LSTM状态管理:
状态组件:特征标志位,记录句子语法属性,比如单复数,性别
比如:Alice -> 女性名词,and Tom -> 复数名词
LSTMCell = 单步LSTM单元(处理单个时间步),LSTM层 = 封装整个序列处理(自动处理时间 步循环)
代码:
class LSTMClassifier(torch.nn.Module):
def __init__(self, vocab_size, embed_dim, hidden_dim, num_class):
super().__init__()
self.hidden_dim = hidden_dim
self.embedding = torch.nn.Embedding(vocab_size, embed_dim)
self.embedding.weight.data = torch.randn_like(self.embedding.weight.data)-0.5
self.rnn = torch.nn.LSTM(embed_dim,hidden_dim,batch_first=True)
self.fc = torch.nn.Linear(hidden_dim, num_class)
def forward(self, x):
batch_size = x.size(0)
x = self.embedding(x)
x,(h,c) = self.rnn(x)
return self.fc(h[-1])
LSTM训练速度慢的话要耐心等
初始阶段准确率提神不明显,要多轮训练
不断调整学习率,考虑用学习率调度器(ReduceLROnPlateau)
优化方法:GPU,梯度裁剪,早停法(监控验证集损失,防过拟合)
net = LSTMClassifier(vocab_size,64,32,len(classes)).to(device)
train_epoch(net,train_loader, lr=0.001)
过程:略
输出:(0.03487814127604167, 0.7728)
Packed Sequences:padding填充导致无效计算(RNN处理填充部分浪费资源),用PS优化
步骤:填充序列(变长序列填充为等长) -> 生成PS(用torch.nn.utils.pack_padded_sequence,将填充后序列转成压缩格式,提供序列的实际长度) -> RNN处理(直接输出PackedSequence到RNN层,只计算有效部分) -> 解包输出(用torch.nn.utils.rnn.pad_packed_sequence恢复填充格式,这一步可选)
比如:填充后批次数据,实际长度[5,3,1]
[[1,2,3,4,5],
[6,7,8,0,0],
[9,0,0,0,0]]
按实际长度动态调整批次大小,避免计算填充部分
存储:压缩序列(将有效数据按时间步优先排列)-> [1,6,9,2,7,3,8,4,5];长度向量(记录各序列实际长度)-> [5,3,1]
def pad_length(b):
# build vectorized sequence
v = [encode(x[1]) for x in b]
# compute max length of a sequence in this minibatch and length sequence itself
len_seq = list(map(len,v))
l = max(len_seq)
return ( # tuple of three tensors - labels, padded features, length sequence
torch.LongTensor([t[0]-1 for t in b]),
torch.stack([torch.nn.functional.pad(torch.tensor(t),(0,l-len(t)),mode='constant',value=0) for t in v]),
torch.tensor(len_seq)
)
train_loader_len = torch.utils.data.DataLoader(train_dataset, batch_size=16, collate_fn=pad_length, shuffle=True)
用PS的LSTM分类器:输入参数(填充后批次数据,序列长度向量),前向传播(嵌入层->生成PS -> LSTM处理 -> 可选解包输出)
class LSTMPackClassifier(torch.nn.Module):
def __init__(self, vocab_size, embed_dim, hidden_dim, num_class):
super().__init__()
self.hidden_dim = hidden_dim
self.embedding = torch.nn.Embedding(vocab_size, embed_dim)
self.embedding.weight.data = torch.randn_like(self.embedding.weight.data)-0.5
self.rnn = torch.nn.LSTM(embed_dim,hidden_dim,batch_first=True)
self.fc = torch.nn.Linear(hidden_dim, num_class)
def forward(self, x, lengths):
batch_size = x.size(0)
x = self.embedding(x)
pad_x = torch.nn.utils.rnn.pack_padded_sequence(x,lengths,batch_first=True,enforce_sorted=False)
pad_x,(h,c) = self.rnn(pad_x)
x, _ = torch.nn.utils.rnn.pad_packed_sequence(pad_x,batch_first=True)
return self.fc(h[-1])
训练:
net = LSTMPackClassifier(vocab_size,64,32,len(classes)).to(device)
train_epoch_emb(net,train_loader_len, lr=0.001,use_pack_sequence=True)
过程:略
结果:(0.029785829671223958, 0.8138166666666666)
use_pack_sequence传递给训练函数要注意pack_padded_sequence要求长度序列张量在CPU上,所以训练函数要避免将长度数据移到GPU
双层RNN,多层RNN:PyTorch设置bidirectional=True或nn.LSTM(..., bidirectional=True)
双层RNN:
同时从序列正向+反向处理,捕获前后文
双向隐藏状态 -- 拼接 --> 双倍长度向量:hidden_size=128 -> 双向后256
多层RNN:
低层提取局部特征,高层捕获抽象模式,设置num_layers=n;前一层输出 = 下一层输入(逐层传递)
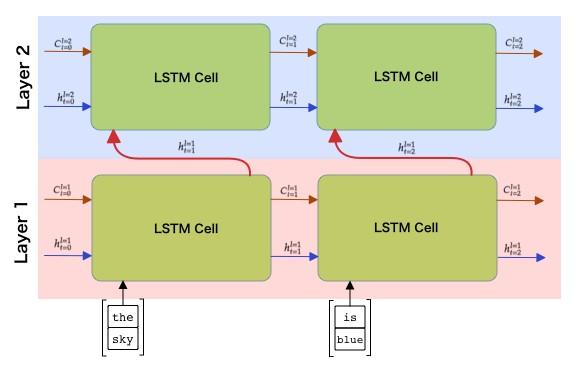
自动叠加多层:RNN/LSTM/GRU构造函数num_layers=n
隐藏状态维度:每层的隐藏状态独立,最终隐藏状态维度=num_layers * hidden_size(单向)或num_layers * 2 * hidden_size(双向);
根据层数调整后续层输出维度(线性分类器)
扩展阅读:
-
RNN TensorFlow