Peter要滑冰(保持平衡)逃避狼的追赶,速度要超过狼
用Q-Learning训练策略,优化动作选择
import sys
!pip install gym pygame
import gym
import matplotlib.pyplot as plt
import numpy as np
import random
建立CartPole环境:
env = gym.make("CartPole-v1")
print(env.action_space)
print(env.observation_space)
print(env.action_space.sample())
env.reset()
for i in range(100):
env.render()
env.step(env.action_space.sample())
env.close()
用step()得观察值+奖励+done,看看是否继续模拟:
env.reset()
done = Falsewhile not done:
env.render()
obs, rew, done, info = env.step(env.action_space.sample())
print(f"{obs} -> {rew}")
env.close()
结果:
[ 0.03044442 -0.19543914 -0.04496216 0.28125618] -> 1.0 [ 0.02653564 -0.38989186 -0.03933704 0.55942606] -> 1.0 [ 0.0187378 -0.19424049 -0.02814852 0.25461393] -> 1.0 [ 0.01485299 -0.38894946 -0.02305624 0.53828712] -> 1.0 [ 0.007074 -0.19351108 -0.0122905 0.23842953] -> 1.0 [ 0.00320378 0.00178427 -0.00752191 -0.05810469] -> 1.0 [ 0.00323946 0.19701326 -0.008684 -0.35315131] -> 1.0 [ 0.00717973 0.00201587 -0.01574703 -0.06321931] -> 1.0 [ 0.00722005 0.19736001 -0.01701141 -0.36082863] -> 1.0 [ 0.01116725 0.39271958 -0.02422798 -0.65882671] -> 1.0 [ 0.01902164 0.19794307 -0.03740452 -0.37387001] -> 1.0 [ 0.0229805 0.39357584 -0.04488192 -0.67810827] -> 1.0 [ 0.03085202 0.58929164 -0.05844408 -0.98457719] -> 1.0 [ 0.04263785 0.78514572 -0.07813563 -1.2950295 ] -> 1.0 [ 0.05834076 0.98116859 -0.10403622 -1.61111521] -> 1.0 [ 0.07796413 0.78741784 -0.13625852 -1.35259196] -> 1.0 [ 0.09371249 0.98396202 -0.16331036 -1.68461179] -> 1.0 [ 0.11339173 0.79106371 -0.1970026 -1.44691436] -> 1.0 [ 0.12921301 0.59883361 -0.22594088 -1.22169133] -> 1.0
打印最大值和最小值:
print(env.observation_space.low)
print(env.observation_space.high)
输出:
[-4.8000002e+00 -3.4028235e+38 -4.1887903e-01 -3.4028235e+38] [4.8000002e+00 3.4028235e+38 4.1887903e-01 3.4028235e+38]
状态离散化:
def discretize(x):
return tuple((x/np.array([0.25, 0.25, 0.01, 0.1])).astype(np.int))
用分箱对状态空间离散化:
def create_bins(i,num):
return np.arange(num+1)*(i[1]-i[0])/num+i[0]
print("Sample bins for interval (-5,5) with 10 bins\n",create_bins((-5,5),10))
ints = [(-5,5),(-2,2),(-0.5,0.5),(-2,2)] # intervals of values for each parameternbins = [20,20,10,10] # number of bins for each parameterbins = [create_bins(ints[i],nbins[i]) for i in range(4)]
def discretize_bins(x):
return tuple(np.digitize(x[i],bins[i]) for i in range(4))
输出:
Sample bins for interval (-5,5) with 10 bins
[-5. -4. -3. -2. -1. 0. 1. 2. 3. 4. 5.]
env.reset()
done = Falsewhile not done:
#env.render()
obs, rew, done, info = env.step(env.action_space.sample())
#print(discretize_bins(obs))
print(discretize(obs))env.close()
输出:
(0, 0, -1, -3)
(0, 0, -2, 0)
(0, 0, -2, -3)
(0, 1, -3, -6)
(0, 2, -4, -9)
(0, 3, -6, -12)
(0, 2, -8, -9)
(0, 3, -10, -13)
(0, 4, -13, -16)
(0, 4, -16, -19)
(0, 4, -20, -17)
(0, 4, -24, -20)
Q-表:
Q = {}
actions = (0,1)
def qvalues(state):
return [Q.get((state,a),0) for a in actions]
Q-Learning:
# hyperparameters
alpha = 0.3
gamma = 0.9
epsilon = 0.90
def probs(v,eps=1e-4):
v = v-v.min()+eps
v = v/v.sum()
return v
Qmax = 0cum_rewards = []rewards = []for epoch in range(100000):
obs = env.reset()
done = False
cum_reward=0
# == do the simulation ==
while not done:
s = discretize(obs)
if random.random()<epsilon:
# exploitation - chose the action according to Q-Table probabilities
v = probs(np.array(qvalues(s)))
a = random.choices(actions,weights=v)[0]
else:
# exploration - randomly chose the action
a = np.random.randint(env.action_space.n)
obs, rew, done, info = env.step(a)
cum_reward+=rew
ns = discretize(obs)
Q[(s,a)] = (1 - alpha) * Q.get((s,a),0) + alpha * (rew + gamma * max(qvalues(ns)))
cum_rewards.append(cum_reward)
rewards.append(cum_reward)
# == Periodically print results and calculate average reward ==
if epoch%5000==0:
print(f"{epoch}: {np.average(cum_rewards)}, alpha={alpha}, epsilon={epsilon}")
if np.average(cum_rewards) > Qmax:
Qmax = np.average(cum_rewards)
Qbest = Q
cum_rewards=[]
输出:
0: 108.0, alpha=0.3, epsilon=0.9
训练
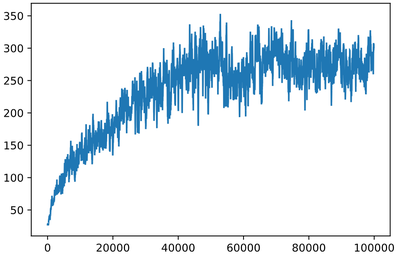
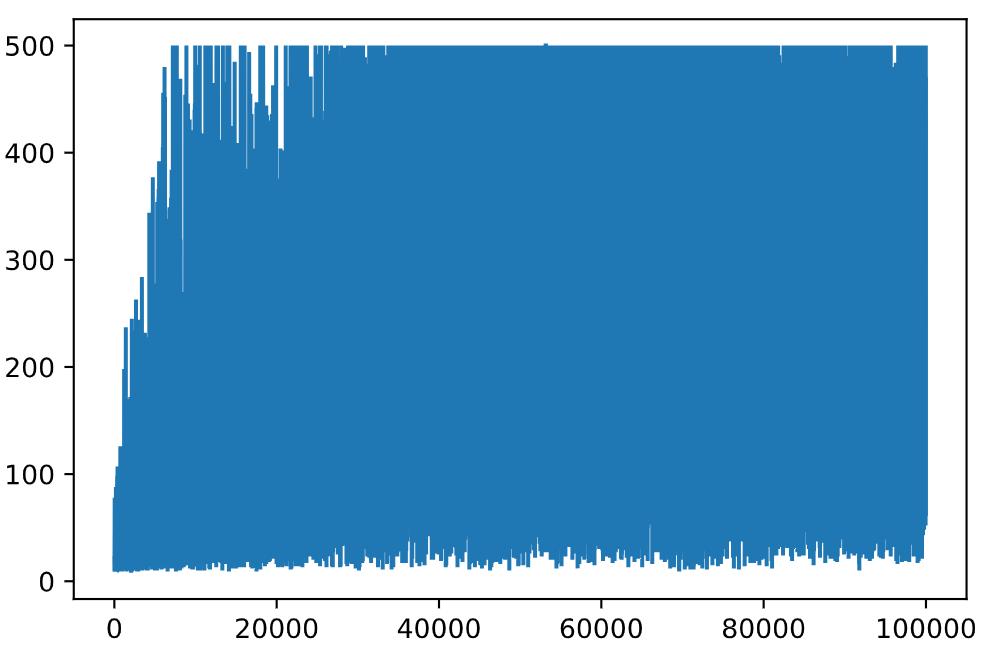
plt.plot(rewards)
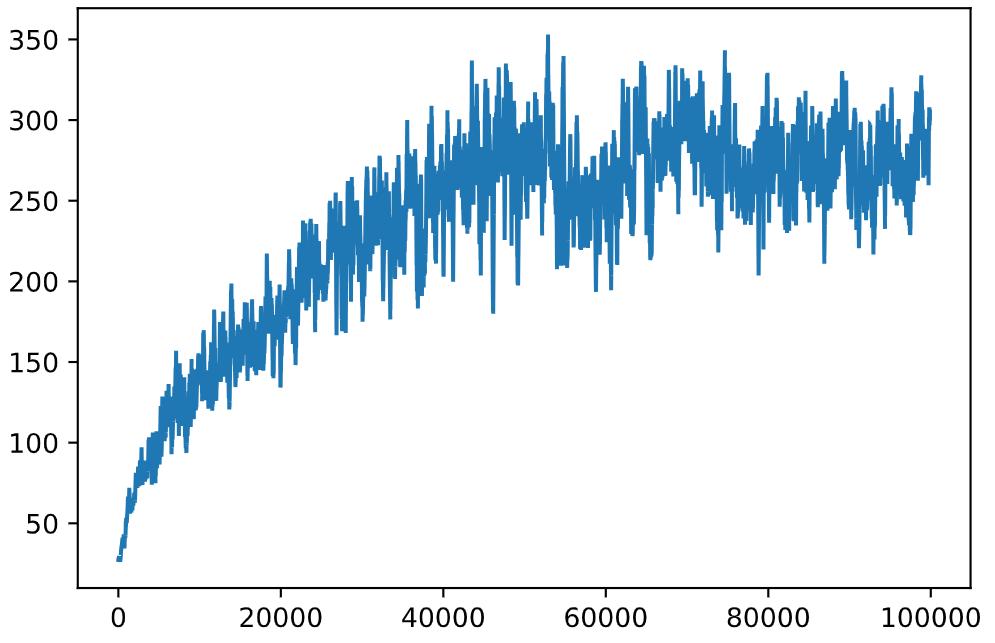
训练曲线平滑:用np.convolve对奖励序列算滑动平均(窗口100),减少随机波动
代码:
def running_average(x,window):
return np.convolve(x,np.ones(window)/window,mode='valid')
plt.plot(running_average(rewards,100))
超参数调整:修改学习率,折扣因子超参数,观察行为变化
动作选择策略:沿用训练时的概率采样策略(Q-Table概率分布)
代码:
obs = env.reset()done = Falsewhile not done:
s = discretize(obs)
env.render()
v = probs(np.array(qvalues(s)))
a = random.choices(actions,weights=v)[0]
obs,_,done,_ = env.step(a)
env.close()
保存GIF格式结果:用PIL库
from PIL import Imageobs = env.reset()done = Falsei=0ims = []while not done:
s = discretize(obs)
img=env.render(mode='rgb_array')
ims.append(Image.fromarray(img))
v = probs(np.array([Qbest.get((s,a),0) for a in actions]))
a = random.choices(actions,weights=v)[0]
obs,_,done,_ = env.step(a)
i+=1env.close()ims[0].save('images/cartpole-balance.gif',save_all=True,append_images=ims[1::2],loop=0,duration=5)print(i)
扩展学习:
-
模拟小车冲出山谷实验
-
TensorFlow训练RL实现CartPole平衡实验
-
CartPole滑冰问题
-
PyTorch训练RL实现CartPole平衡实验