RNN/LSTM的缺点:所有输入词对输出的影响相同,长序列处理能力差(编码-解码结构容易遗忘序列开头),机器翻译序列任务表现差
解决:引入注意力机制 + Transformer
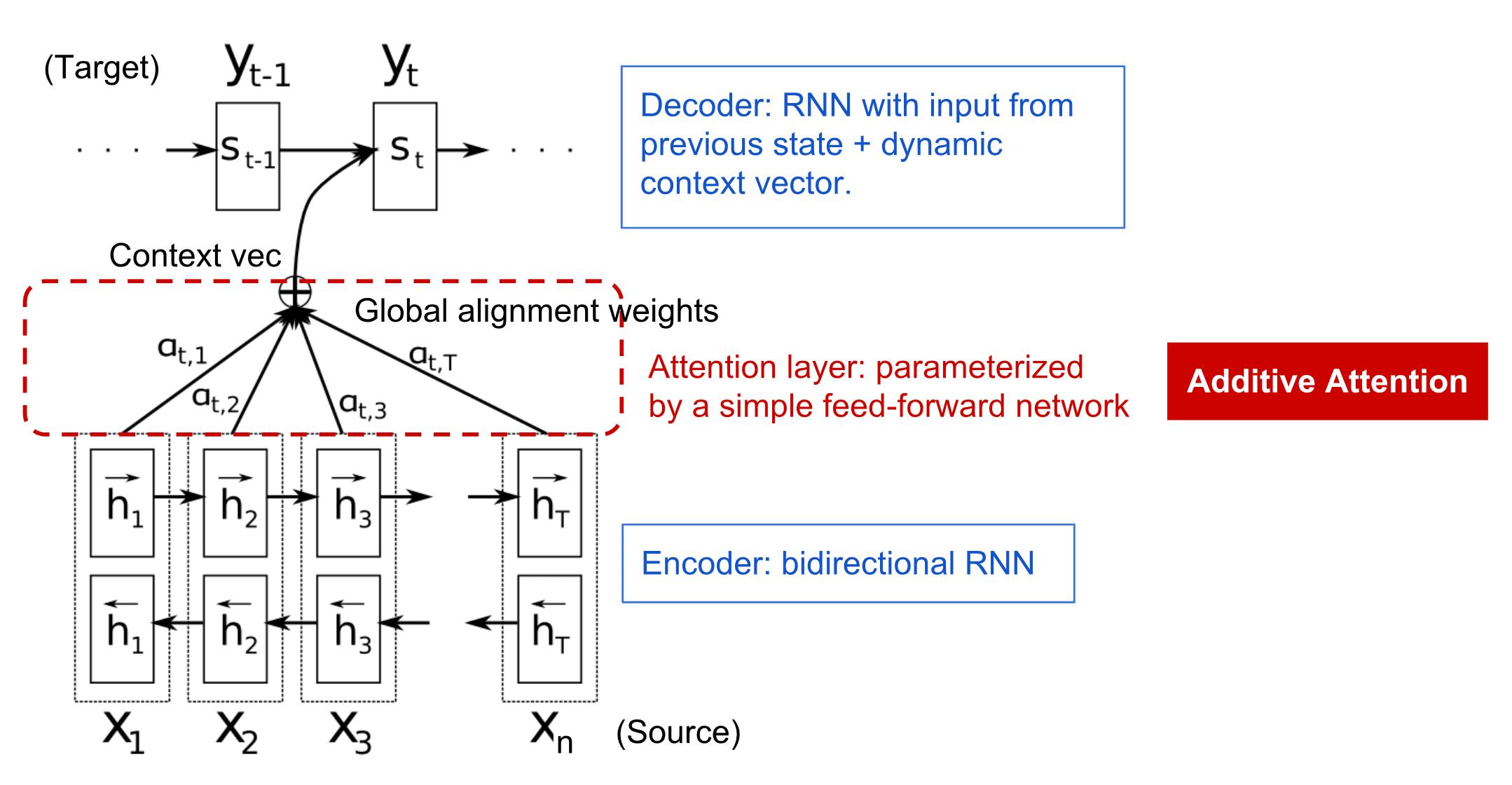
注意力机制:输入词赋动态权重at,i,增强关键词对输出的影响;解码生成输出yt 结合所有输出隐藏状态hi(按权重甲加权)
过程:编码器-快捷连接-解码器,用输入蓄力的中间状态;避免依赖单一最终隐藏状态
注意力矩阵:矩阵元素{αi,j} = 生成第i输出词时,对第j输入词的关注程度(颜色浅深 = 注意力权重)

注意力增加NLP任务性能(翻译,生成),动态捕捉长距离依赖,替代RNN固定状态传递
RNN不能并行化,训练低效,参数多(引入注意力参数变多,难扩展)
Transformer支持自注意力 + 位置编码
自注意力:代替RNN,并行处理序列
位置编码:注入序列位置
(GPT用的就是Transformer)
Transformer模型:位置编码 + 自注意力 + 并行计算 + 上下文窗口
并行计算:全连接结构让序列并处理;输入位置独立映射到输出,支持大模型
上下文窗口:关注当前窗口的所有词,突破RNN长程依赖限制
动图结构:

多头注意力:多个注意力头学习词间不同关系(语法,语义)
BERT架构:基础(12层Transformer编码器),大型(24层)
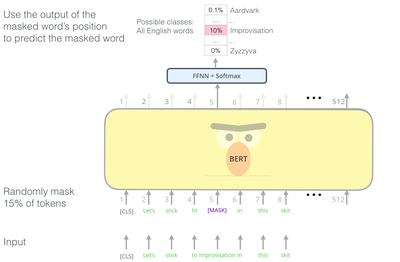
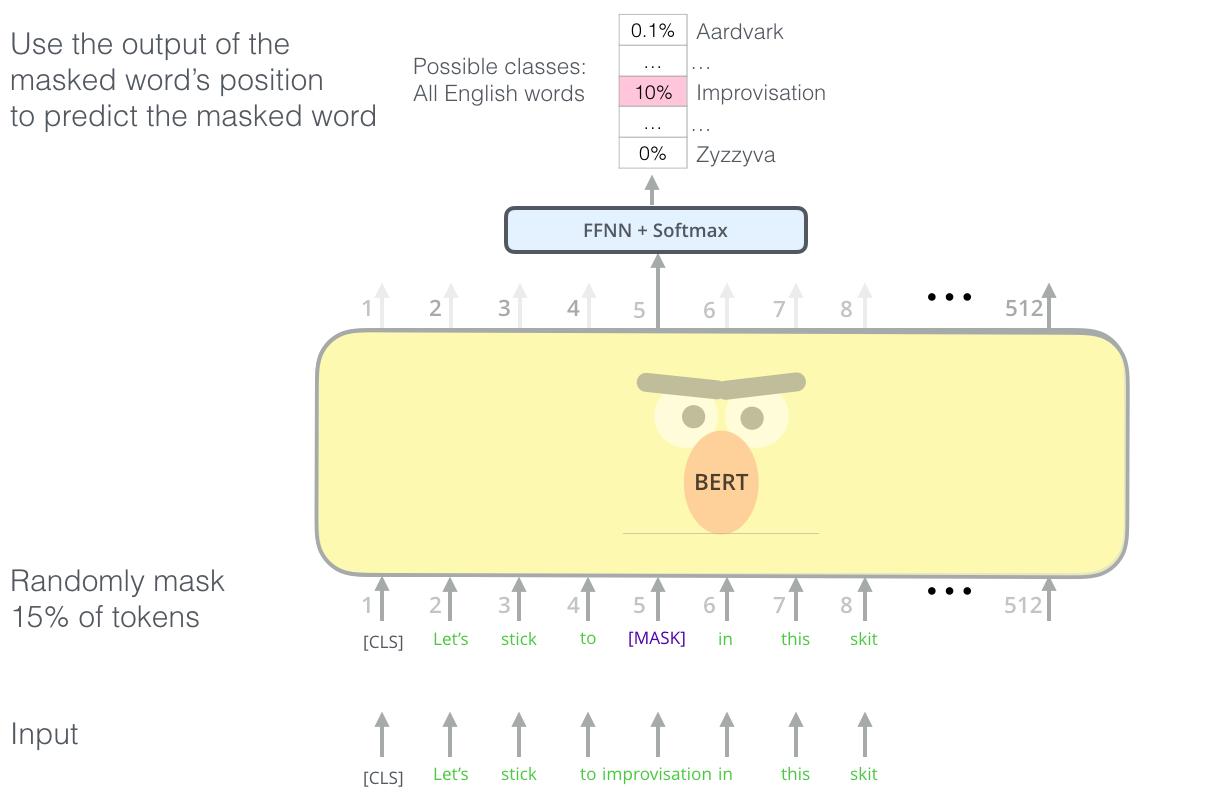
预训练任务:掩码语言模型MLM,预测句中被遮蔽的词
训练数据:维基百科 + 书,无监督
预训练后用微调适配下游任务(分类,问答)
Transformer架构变体:BERT,DistilBERT,BigBird,GPT3等都可以微调,Huggingface的库有这些模型的PyTorch资源
BERT文本分类:导入HuggingFace Transformer库,加载AG News数据集;预处理分词,建模,微调,评估预测(准确率,训练好的模型新样本分类)
预处理:用BERT分词器BertTokenizer处理文本(加特殊标记),截断或者填充固定长度(512词)
建模:加载预训练BERT模型BertForSequenceClassification
微调:定义优化器,学习率调度,循环训练(算损失,反向传播,更新参数)
import torch
import torchtext
from torchnlp import *import transformerstrain_dataset, test_dataset, classes, vocab = load_dataset()
vocab_len = len(vocab)
加载分词器:用BertTokenizer.from_pretrained('bert-base-uncased')加载,预训练BERT模型匹配的分词器
用bert-base-uncased自动下载预训练模型+文件
自定义模型加载:本地目录要有分词器配置(vocab.txt) + 模型配置文件(config.json) + 模型权重文件(pytorch_model.bin)
代码:
# To load the model from Internet repository using model name.
# Use this if you are running from your own copy of the notebooks
bert_model = 'bert-base-uncased'
# To load the model from the directory on disk. Use this for Microsoft Learn module, because we have
# prepared all required files for you.
bert_model = './bert'
tokenizer = transformers.BertTokenizer.from_pretrained(bert_model)
MAX_SEQ_LEN = 128PAD_INDEX = tokenizer.convert_tokens_to_ids(tokenizer.pad_token)
UNK_INDEX = tokenizer.convert_tokens_to_ids(tokenizer.unk_token)
分词器对象有编码文本函数encode()
tokenizer.encode('PyTorch is a great framework for NLP')
输出:[101, 1052, 22123, 2953, 2818, 2003, 1037, 2307, 7705, 2005, 17953, 2361, 102]
创建迭代器(训练时访问数据),定义填充函数:
def pad_bert(b):
# b is the list of tuples of length batch_size
# - first element of a tuple = label,
# - second = feature (text sequence)
# build vectorized sequence
v = [tokenizer.encode(x[1]) for x in b]
# compute max length of a sequence in this minibatch
l = max(map(len,v))
return ( # tuple of two tensors - labels and features
torch.LongTensor([t[0] for t in b]),
torch.stack([torch.nn.functional.pad(torch.tensor(t),(0,l-len(t)),mode='constant',value=0) for t in v])
)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=8, collate_fn=pad_bert, shuffle=True)test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=8, collate_fn=pad_bert)
用BertForSequenceClassification,bert-base-uncased(简称BERT)加载预训练模型;指定分类数4
模型 = BERT基础模型 + 顶层分类器;分类器权重随机初始化,要用微调训练更新
微调要训练未初始化参数(分类层权重),如果分类层未初始化警告可以忽略
model = transformers.BertForSequenceClassification.from_pretrained(bert_model,num_labels=4).to(device)
BERT微调训练:设置学习率(小的2e-5~5e-5,避免破坏预训练权重)-> 训练循环(前向传播,法相传播,优化,算准确率)-> 持续监控(每隔report_freq次输出平均损失+准确率)
用max_steps=1000控制时间
梯度累积:多个小批次梯度更新,模拟更大批次训练
混合精度训练用torch.cuda.amp加速
用GPU,大的用分布式
代码:
optimizer = torch.optim.Adam(model.parameters(), lr=2e-5)
report_freq = 50iterations = 500 # make this larger to train for longer time!
model.train()
i,c = 0,0acc_loss = 0acc_acc = 0
for labels,texts in train_loader:
labels = labels.to(device)-1 # get labels in the range 0-3
texts = texts.to(device)
loss, out = model(texts, labels=labels)[:2]
labs = out.argmax(dim=1)
acc = torch.mean((labs==labels).type(torch.float32))
optimizer.zero_grad()
loss.backward()
optimizer.step()
acc_loss += loss
acc_acc += acc
i+=1
c+=1
if i%report_freq==0:
print(f"Loss = {acc_loss.item()/c}, Accuracy = {acc_acc.item()/c}")
c = 0
acc_loss = 0
acc_acc = 0
iterations-=1
if not iterations:
break
输出:
Loss = 1.1254194641113282, Accuracy = 0.585
Loss = 0.6194715118408203, Accuracy = 0.83
Loss = 0.46665248870849607, Accuracy = 0.8475
Loss = 0.4309701919555664, Accuracy = 0.8575
Loss = 0.35427074432373046, Accuracy = 0.8825
Loss = 0.3306886291503906, Accuracy = 0.8975
Loss = 0.30340143203735354, Accuracy = 0.8975
Loss = 0.26139299392700194, Accuracy = 0.915
Loss = 0.26708646774291994, Accuracy = 0.9225
Loss = 0.3667240524291992, Accuracy = 0.8675
BERT分类准确率高是因为预训练前结构已成熟,只用微调分类层就可以
基础bert-base参数量1.1亿 -> 中等计算资源
大型bert-large有3.4 -> 高等
扩展可以用更大模型(RoBERTa,ALBERT)提性能,也可以用混合精度训练AMP减现存占用
模型评估:
切换评估模式:禁用Dropout + BatchNorm随机性
禁用梯度计算:减少内存消耗,计算加速
遍历测试集:逐批次处理数据,算损失 + 准确率
输出结果
代码:
model.eval()iterations = 100acc = 0i = 0
for labels,texts in test_loader:
labels = labels.to(device)-1
texts = texts.to(device)
_, out = model(texts, labels=labels)[:2]
labs = out.argmax(dim=1)
acc += torch.mean((labs==labels).type(torch.float32))
i+=1
if i>iterations: break
print(f"Final accuracy: {acc.item()/i}")
输出:
Final accuracy: 0.9047029702970297
扩展阅读:
-
Transformer TensorFlow