简单文本生成模型,字符级网络,逐字母生成文本;训练时将语料拆成字符序列
import torch
import torchtext
import numpy as np
from torchnlp import *train_dataset,test_dataset,classes,vocab = load_dataset()
字符词表:定义分词器 -> 文本拆成字符
def char_tokenizer(words):
return list(words) #[word for word in words]
counter = collections.Counter()for (label, line) in train_dataset:
counter.update(char_tokenizer(line))vocab = torchtext.vocab.vocab(counter)
vocab_size = len(vocab)print(f"Vocabulary size = {vocab_size}")
print(f"Encoding of 'a' is {vocab.get_stoi()['a']}")
print(f"Character with code 13 is {vocab.get_itos()[13]}")
词表情况:
Vocabulary size = 82
Encoding of 'a' is 1
Character with code 13 is c
从数据集编码文本:
def enc(x):
return torch.LongTensor(encode(x,voc=vocab,tokenizer=char_tokenizer))
enc(train_dataset[0][1])
输出:
tensor([ 0, 1, 2, 2, 3, 4, 5, 6, 3, 7, 8, 1, 9, 10, 3, 11, 2, 1,
12, 3, 7, 1, 13, 14, 3, 15, 16, 5, 17, 3, 5, 18, 8, 3, 7, 2,
1, 13, 14, 3, 19, 20, 8, 21, 5, 8, 9, 10, 22, 3, 20, 8, 21, 5,
8, 9, 10, 3, 23, 3, 4, 18, 17, 9, 5, 23, 10, 8, 2, 2, 8, 9,
10, 24, 3, 0, 1, 2, 2, 3, 4, 5, 9, 8, 8, 5, 25, 10, 3, 26,
12, 27, 16, 26, 2, 27, 16, 28, 29, 30, 1, 16, 26, 3, 17, 31, 3, 21,
2, 5, 9, 1, 23, 13, 32, 16, 27, 13, 10, 24, 3, 1, 9, 8, 3, 10,
8, 8, 27, 16, 28, 3, 28, 9, 8, 8, 16, 3, 1, 28, 1, 27, 16, 6])
训练GN :取长度n chars字符序列 = 输入,网络 = 每个输入字符生成下一个输出字符
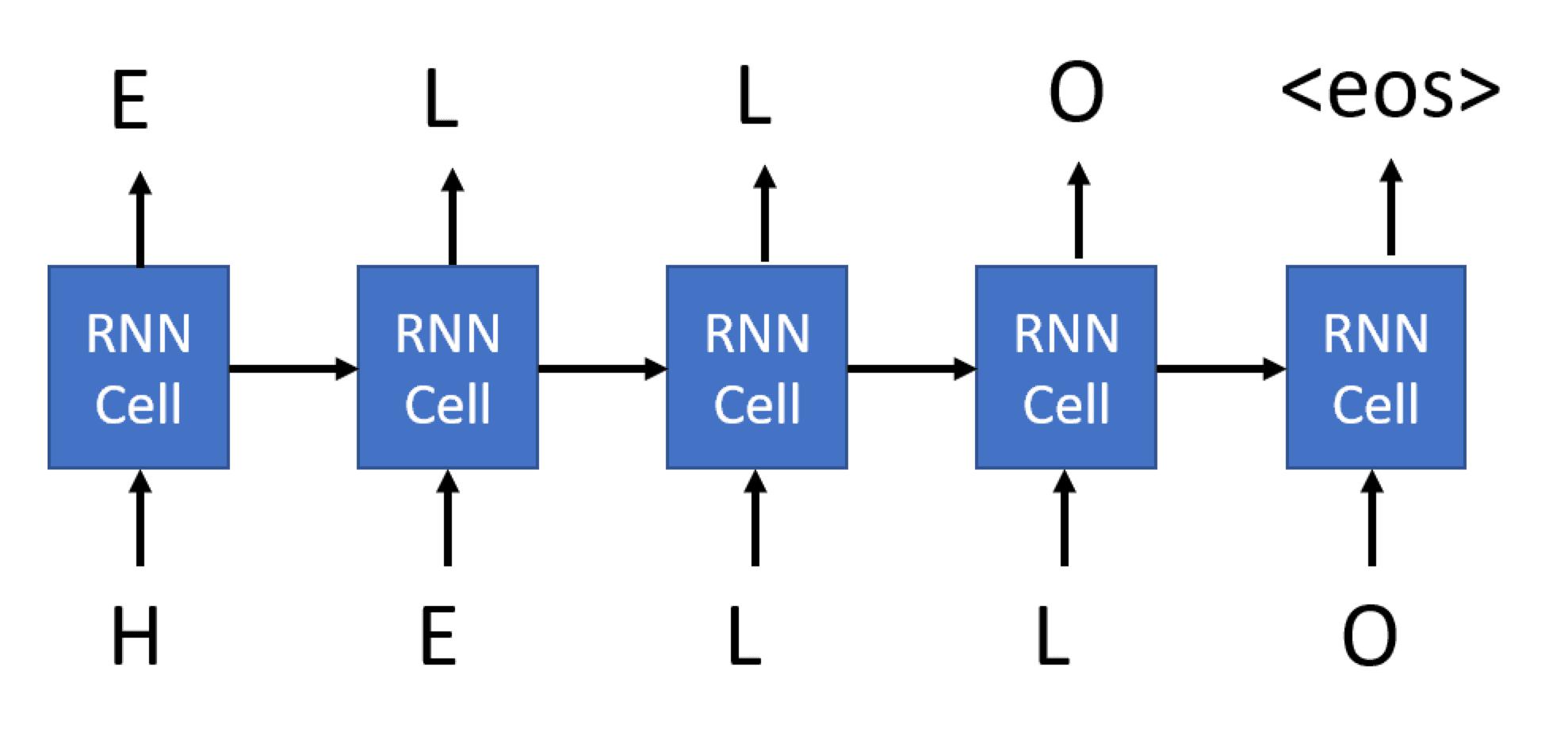
训练数据生成:滑动窗口截取连续字符序列,输入和输出错位一位
序列长度:nchars个字符 -> 训练样本含n chars = 输入输出(输出 = 输入序列左移一位)
小批次构建:长度=1文本生成1-nchars个子序列;子序列=小批次样本
特殊字符:用结束符终止生成
代码:
nchars = 100
def get_batch(s,nchars=nchars):
ins = torch.zeros(len(s)-nchars,nchars,dtype=torch.long,device=device)
outs = torch.zeros(len(s)-nchars,nchars,dtype=torch.long,device=device)
for i in range(len(s)-nchars):
ins[i] = enc(s[i:i+nchars])
outs[i] = enc(s[i+1:i+nchars+1])
return ins,outs
get_batch(train_dataset[0][1])
输出:
(tensor([[ 0, 1, 2, ..., 28, 29, 30],
[ 1, 2, 2, ..., 29, 30, 1],
[ 2, 2, 3, ..., 30, 1, 16],
...,
[20, 8, 21, ..., 1, 28, 1],
[ 8, 21, 5, ..., 28, 1, 27],
[21, 5, 8, ..., 1, 27, 16]]),
tensor([[ 1, 2, 2, ..., 29, 30, 1],
[ 2, 2, 3, ..., 30, 1, 16],
[ 2, 3, 4, ..., 1, 16, 26],
...,
[ 8, 21, 5, ..., 28, 1, 27],
[21, 5, 8, ..., 1, 27, 16],
[ 5, 8, 9, ..., 27, 16, 6]]))
GN基于LSTM(可用RNN/GRU)
输入:字符索引直接输入 -> one_hot()独热编码,不用嵌入层
输出:线性层把隐藏状态映射大独热编码输出 -> 预测下一个字符
(小词表适合独热)
代码:
class LSTMGenerator(torch.nn.Module):
def __init__(self, vocab_size, hidden_dim):
super().__init__()
self.rnn = torch.nn.LSTM(vocab_size,hidden_dim,batch_first=True)
self.fc = torch.nn.Linear(hidden_dim, vocab_size)
def forward(self, x, s=None):
x = torch.nn.functional.one_hot(x,vocab_size).to(torch.float32)
x,s = self.rnn(x,s)
return self.fc(x),s
文本生成函数逻辑:
输入:初始字符串start,生成长度size
过程:初始化状态(start->网络 -> 最终隐藏状态)-> 自回归生成(循环size次,每次用当前隐藏状态预测下一个字符,取argmax/采样;预测字符追加到结果列表;更新隐藏状态,输入新字符继续生成)
def generate(net,size=100,start='today '):
chars = list(start)
out, s = net(enc(chars).view(1,-1).to(device))
for i in range(size):
nc = torch.argmax(out[0][-1])
chars.append(vocab.get_itos()[nc])
out, s = net(nc.view(1,-1),s)
return ''.join(chars)
训练:前向传播 -> 计算损失(交叉熵;输入未归一化的网络输出 + 目标字符索引) -> 反向传播 -> 优化参数
数据限制:samples_to_train调整
扩展训练:外层循环多个epoch,多次遍历整个数据集
net = LSTMGenerator(vocab_size,64).to(device)
samples_to_train = 10000optimizer = torch.optim.Adam(net.parameters(),0.01)loss_fn = torch.nn.CrossEntropyLoss()net.train()for i,x in enumerate(train_dataset):
# x[0] is class label, x[1] is text
if len(x[1])-nchars<10:
continue
samples_to_train-=1
if not samples_to_train: break
text_in, text_out = get_batch(x[1])
optimizer.zero_grad()
out,s = net(text_in)
loss = torch.nn.functional.cross_entropy(out.view(-1,vocab_size),text_out.flatten()) #cross_entropy(out,labels)
loss.backward()
optimizer.step()
if i%1000==0:
print(f"Current loss = {loss.item()}")
print(generate(net))
结果:略
生成模型优化:改进小批次生成,多层LSTM,单元类型实验,隐藏层大小调整,学习率调度,正则化,温度采样
改进小批量生成:单样本生成小批次大小不一效率低 -> 解:多文本合成长序列->统一生成输入输出对 -> 打乱后再分批次;每个批次大小要相同(提GPU)
多层LSTM:堆叠2-3层LSTM(低层捕获音节/局部模式,高层建模词语结合),设置num_layers
单元类型实验:对比LSTM和GRU,选最优的单元
隐藏层大小调整:太大会过拟合,太小不好捕模式(生成质量差),交叉验证选合适尺寸
学习率调度:动态调整lr加速收敛
正则化:加Dropout层防过拟合
温度采样:生成时引入随机性
贪婪采样(只选最高概率的字符)会文本重复循环,按概率分布随机采样可解
温度参数:调整概率分布平滑度,高温(T>1,分布平缓=多样性高,随机性强),低温(T<1,分布尖锐 = 确定性高,偏向高概率字符)
采样步骤:模型输出logits / T -> softmax得概率分布 -> torch.multinomial按分布采样字符索引
代码:
def generate_soft(net,size=100,start='today ',temperature=1.0):
chars = list(start)
out, s = net(enc(chars).view(1,-1).to(device))
for i in range(size):
#nc = torch.argmax(out[0][-1])
out_dist = out[0][-1].div(temperature).exp()
nc = torch.multinomial(out_dist,1)[0]
chars.append(vocab.get_itos()[nc])
out, s = net(nc.view(1,-1),s)
return ''.join(chars)
for i in [0.3,0.8,1.0,1.3,1.8]:
print(f"--- Temperature = {i}\n{generate_soft(net,size=300,start='Today ',temperature=i)}\n")
过程:略
温度:
T=1.0 = 标准采样,原始概率分布选字符
T->∞ = 趋近均匀,完全随机选择 = 文本无意义
T->0 = 贪婪采样
创造性任务选高温度,1.0-1.5
确定性输出(保守),0.5-1.0
高温:T=2.0,随机性强,可能有语法错误
低温:T=0.5,连贯,可能重复固定模式
扩展学习:
-
GN TensorFlow
-
RNN单词级文本生成