用AG News数据集
import torch
import torchtext
import numpy as np
from torchnlp import *train_dataset, test_dataset, classes, vocab = load_dataset()
vocab_size = len(vocab)
print("Vocab size = ",vocab_size)
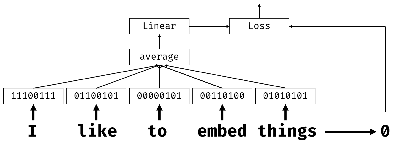
嵌入:词语表示成低维稠密向量(不是高维稀疏 独热编码),捕捉语义
嵌入层:单词以索引形式输出,映射成稠密向量(维度=embedding_size)
嵌入Bow:替代BoW;每个词转嵌入向量 -> 聚合(求和/平均/最大值) -> 文本表示
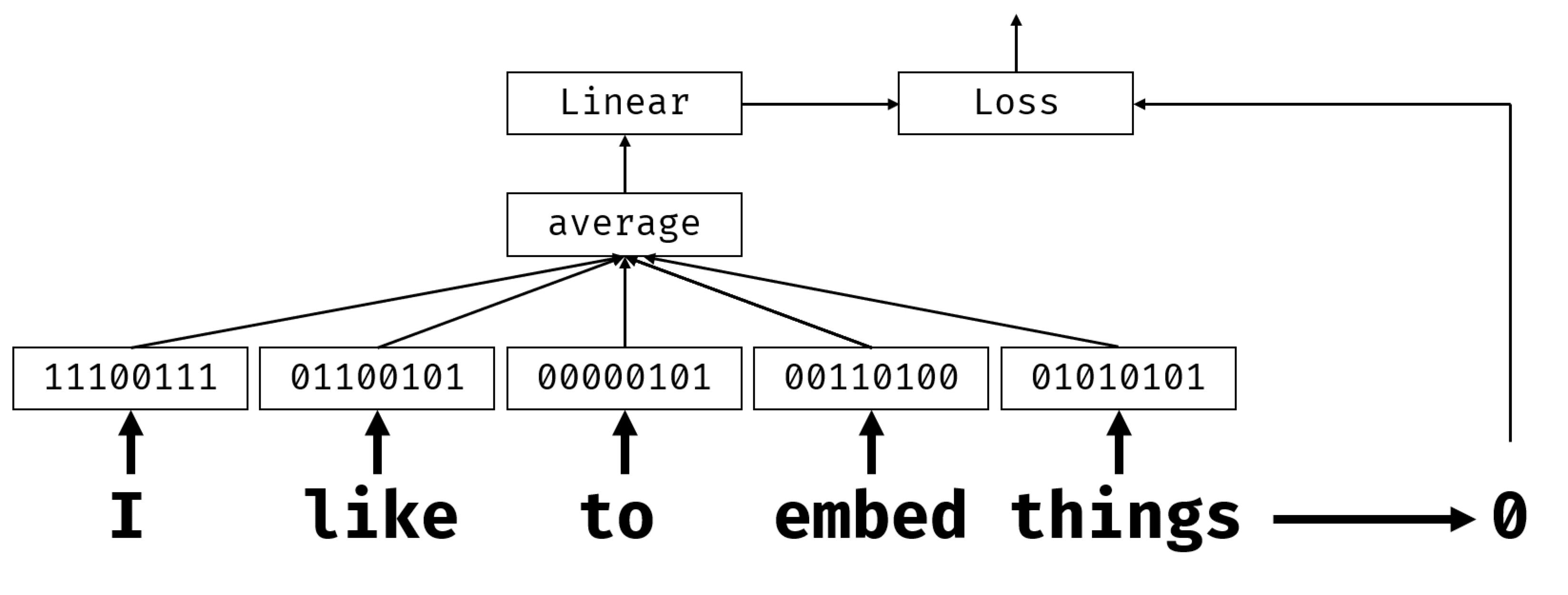
分类器神经网络结构:嵌入式->聚合层->线性分类器
处理变长序列:用嵌入层每个样本单词数不同,要处理变长序列
数据加载时用collate_fn对批次样本填充padding
def padify(b):
# b is the list of tuples of length batch_size
# - first element of a tuple = label,
# - second = feature (text sequence)
# build vectorized sequence
v = [encode(x[1]) for x in b]
# first, compute max length of a sequence in this minibatch
l = max(map(len,v))
return ( # tuple of two tensors - labels and features
torch.LongTensor([t[0]-1 for t in b]),
torch.stack([torch.nn.functional.pad(torch.tensor(t),(0,l-len(t)),mode='constant',value=0) for t in v])
)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=16, collate_fn=padify, shuffle=True)
训练嵌入分类器:定义好数据加载器dataloader后,用前一个单元编写的训练函数来训练
net = EmbedClassifier(vocab_size,32,len(classes)).to(device)
train_epoch(net,train_loader, lr=1, epoch_size=25000)
输出:
(0.889799795315499, 0.7623160588611644)
仅训练2.5万数据,不足一轮,反复训练编写多轮训练函数,调整学习率参数提升准确率
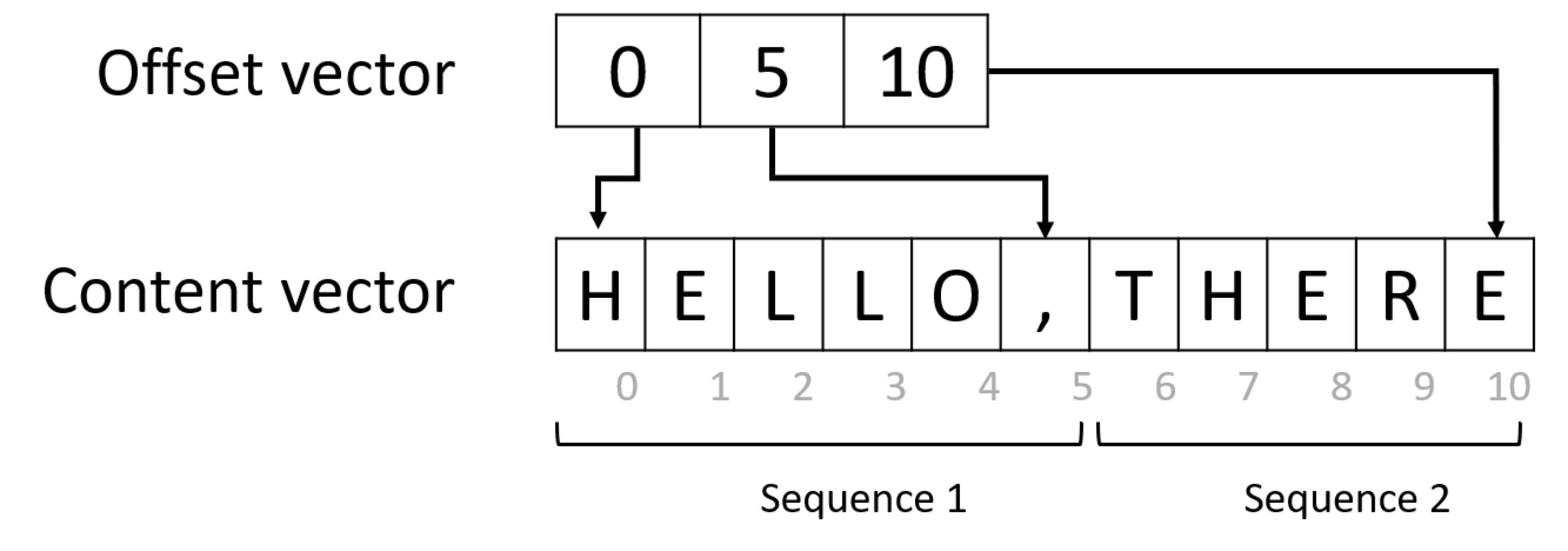
字符序列处理:原理是用偏移向量表示序列
本实验用的例子是词序列,但原理一样
用EmbeddingBag层处理偏移表示(~Embedding),输入(内容向量+偏移向量),内置聚合层(均值,求和,最大值)
用EmbeddingBag调整网络:
class EmbedClassifier(torch.nn.Module):
def __init__(self, vocab_size, embed_dim, num_class):
super().__init__()
self.embedding = torch.nn.EmbeddingBag(vocab_size, embed_dim)
self.fc = torch.nn.Linear(embed_dim, num_class)
def forward(self, text, off):
x = self.embedding(text, off)
return self.fc(x)
在训练准备数据集时,用一个转换函数生成偏移向量
代码:
def offsetify(b):
# first, compute data tensor from all sequences
x = [torch.tensor(encode(t[1])) for t in b]
# now, compute the offsets by accumulating the tensor of sequence lengths
o = [0] + [len(t) for t in x]
o = torch.tensor(o[:-1]).cumsum(dim=0)
return (
torch.LongTensor([t[0]-1 for t in b]), # labels
torch.cat(x), # text
o
)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=16, collate_fn=offsetify, shuffle=True)
只接收两个参数(数据向量,偏移向量;而且尺寸不同)
数据加载器返三个值(文本+偏移向量=特征)
net = EmbedClassifier(vocab_size,32,len(classes)).to(device)
def train_epoch_emb(net,dataloader,lr=0.01,optimizer=None,loss_fn = torch.nn.CrossEntropyLoss(),epoch_size=None, report_freq=200):
optimizer = optimizer or torch.optim.Adam(net.parameters(),lr=lr)
loss_fn = loss_fn.to(device)
net.train()
total_loss,acc,count,i = 0,0,0,0
for labels,text,off in dataloader:
optimizer.zero_grad()
labels,text,off = labels.to(device), text.to(device), off.to(device)
out = net(text, off)
loss = loss_fn(out,labels) #cross_entropy(out,labels)
loss.backward()
optimizer.step()
total_loss+=loss
_,predicted = torch.max(out,1)
acc+=(predicted==labels).sum()
count+=len(labels)
i+=1
if i%report_freq==0:
print(f"{count}: acc={acc.item()/count}")
if epoch_size and count>epoch_size:
break
return total_loss.item()/count, acc.item()/count
train_epoch_emb(net,train_loader, lr=4, epoch_size=25000)
输出:
(22.771553103007037, 0.7551983365323096)
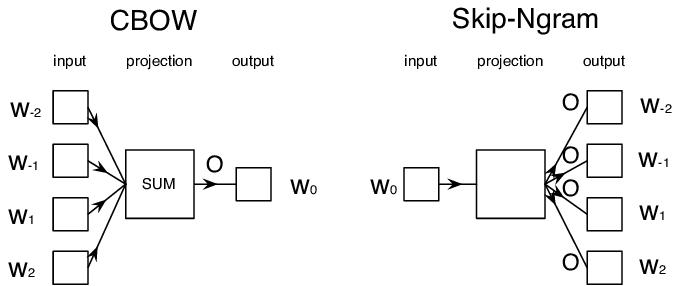
语义嵌入:Word2Vec;学语义化词向量(相似词/近义词向量距离更近 = 欧氏距离);用预训练;有2个架构(CBoW,Skip-Gram)
CBoW(连续词袋):用上下文/窗口词预测中心词;快
公式: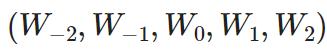 ,比如 用-2,-1,1,2预测0
,比如 用-2,-1,1,2预测0
Skip-Gram(连续跳字):中心词预测上下文词;满,低频词表征好
公式: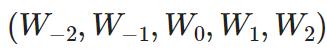 ,比如 用0预测-2,-1,1,2
,比如 用0预测-2,-1,1,2
Google News数据集预训练word2vec嵌入实验,用gensim库实现;找与neural最像的词:
import gensim.downloader as api
w2v = api.load('word2vec-google-news-300')
for w,p in w2v.most_similar('neural'):
print(f"{w} -> {p}")
词表:
neuronal -> 0.7804799675941467 neurons -> 0.7326500415802002 neural_circuits -> 0.7252851724624634 neuron -> 0.7174385190010071 cortical -> 0.6941086649894714 brain_circuitry -> 0.6923246383666992 synaptic -> 0.6699118614196777 neural_circuitry -> 0.6638563275337219 neurochemical -> 0.6555314064025879 neuronal_activity -> 0.6531826257705688
从单词中计算向量嵌入,用来分类模型训练:
w2v.word_vec('play')[:20] //假设20维
输出:
array([ 0.01226807, 0.06225586, 0.10693359, 0.05810547, 0.23828125,
0.03686523, 0.05151367, -0.20703125, 0.01989746, 0.10058594,
-0.03759766, -0.1015625 , -0.15820312, -0.08105469, -0.0390625 ,
-0.05053711, 0.16015625, 0.2578125 , 0.10058594, -0.25976562],
dtype=float32)
语义嵌入:可用向量运算调整语义
如:找向量最接近king和woman,但是远离man的词
w2v.most_similar(positive=['king','woman'],negative=['man'])[0]
输出:('queen', 0.7118192911148071)
词嵌入方法/模型:
CBoW/Skip-Gram(Word2Vec):局部上下文预测,不需要全局信息
FastText:引入子词n-gram向量,增强未登录词处理能力
GloVe:共现矩阵分解,结合全局统计生成词向量
可用gensim切换不同嵌入模型
用预训练嵌入:比如(word2vec)载入嵌入层权重矩阵,但是预训练词表可能跟语料库词表不匹配,未匹配的词随机初始化权重
embed_size = len(w2v.get_vector('hello'))print(f'Embedding size: {embed_size}')
net = EmbedClassifier(vocab_size,embed_size,len(classes))
print('Populating matrix, this will take some time...',end='')found, not_found = 0,0for i,w in enumerate(vocab.get_itos()):
try:
net.embedding.weight[i].data = torch.tensor(w2v.get_vector(w))
found+=1
except:
net.embedding.weight[i].data = torch.normal(0.0,1.0,(embed_size,))
not_found+=1
print(f"Done, found {found} words, {not_found} words missing")net = net.to(device)
报告:
Embedding size: 300
Populating matrix, this will take some time...Done, found 41080 words, 54732 words missing
训练模型:
嵌入式尺寸增大(参数增加),训练时间长,要多训练数据才能避免过拟合
报告:
vocab = torchtext.vocab.GloVe(name='6B', dim=50)
3200: acc=0.6359375
6400: acc=0.68109375
9600: acc=0.7067708333333333
12800: acc=0.723671875
16000: acc=0.73625
19200: acc=0.7463541666666667
22400: acc=0.7560714285714286
结果:(214.1013875559821, 0.7626759436980166)
预训练词表与当前任务词表差异大,这样的话准确率提升有限:
解决:重新训练Word2Vec(词表重新训练嵌入),对齐词表(记载数据集用预训练模型的词表:用torchtext,指定GlobVe嵌入的词表)
vocab = torchtext.vocab.GloVe(name='6B', dim=50)
词表操作:
vocab.stoi = 词到索引的字典
vocab.itos = 索引到词的列表
vocab.vectors = 嵌入向量数组,用vocab.vectors[vocab.stoi[词]]获取词向量
(向量运算验证king - man + woman = queen,要微调系数)
# get the vector corresponding to kind-man+woman
qvec = vocab.vectors[vocab.stoi['king']]-vocab.vectors[vocab.stoi['man']]+1.3*vocab.vectors[vocab.stoi['woman']]
# find the index of the closest embedding vector
d = torch.sum((vocab.vectors-qvec)**2,dim=1)
min_idx = torch.argmin(d)
# find the corresponding wordvocab.itos[min_idx]
结果:queen
先用GloVe词表对数据集编码,再用GloVe嵌入训练分类器:
def offsetify(b):
# first, compute data tensor from all sequences
x = [torch.tensor(encode(t[1],voc=vocab)) for t in b] # pass the instance of vocab to encode function!
# now, compute the offsets by accumulating the tensor of sequence lengths
o = [0] + [len(t) for t in x]
o = torch.tensor(o[:-1]).cumsum(dim=0)
return (
torch.LongTensor([t[0]-1 for t in b]), # labels
torch.cat(x), # text
o
)
所有词向量存在vocab.vectors矩阵,复制到嵌入层的权重:
net = EmbedClassifier(len(vocab),len(vocab.vectors[0]),len(classes))
net.embedding.weight.data = vocab.vectors
net = net.to(device)
训练模型:
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=16, collate_fn=offsetify, shuffle=True)
train_epoch_emb(net,train_loader, lr=4, epoch_size=25000)
过程:
3200: acc=0.6271875 6400: acc=0.68078125 9600: acc=0.7030208333333333 12800: acc=0.71984375 16000: acc=0.7346875 19200: acc=0.7455729166666667 22400: acc=0.7529464285714286
结果:
(35.53972978646833, 0.7575175943698017)
准确率不涨:可能是数据集中部分词末在GloVe里,被忽略
解决:再数据集上自训练嵌入
上下文嵌入:
传统嵌入不区分多义词(play有很多意思),因为所有语义编码成同个向量
解决:用上下文嵌入(如BERT)
扩展阅读:
-
TensorFlow嵌入式