AG_NEWS数据集,做新闻标题分类(世界,体育,商业,科技):
import torch
import torchtext
import os
import collectionsos.makedirs('./data',exist_ok=True)
train_dataset, test_dataset = torchtext.datasets.AG_NEWS(root='./data')
classes = ['World', 'Sports', 'Business', 'Sci/Tech']
train_dataset和test_dataset每个样本都是(标签号,文本)元组
list(train_dataset)[0]
输出:
(3, "Wall St. Bears Claw Back Into the Black (Reuters) Reuters - Short-sellers, Wall Street's dwindling\\band of ultra-cynics, are seeing green again.")
输出所有标题:
for i,x in zip(range(5),train_dataset):
print(f"**{classes[x[0]]}** -> {x[1]}")
结果:略
转化成list:
train_dataset, test_dataset = torchtext.datasets.AG_NEWS(root='./data')
train_dataset = list(train_dataset)test_dataset = list(test_dataset)
分词Tokenization:文本拆成单词或子词tokens
构建词表Vocabulary:所有tokens分配唯一索引,形成词表
将文本转换成可输入模型的张量(用数值表示)
tokenizer = torchtext.data.utils.get_tokenizer('basic_english')
tokenizer('He said: hello')
输出:['he', 'said', 'hello']
代码:
counter = collections.Counter()
for (label, line) in train_dataset:
counter.update(tokenizer(line))
vocab = torchtext.vocab.vocab(counter, min_freq=1)
用词表将token化的字符串转成数字:
vocab_size = len(vocab)print(f"Vocab size if {vocab_size}")
stoi = vocab.get_stoi() # dict to convert tokens to indices
def encode(x):
return [stoi[s] for s in tokenizer(x)]
encode('I love to play with my words')
输出:[599, 3279, 97, 1220, 329, 225, 7368]
词袋模型bag of words(BoW):文本表示->向量(数值数组),算传统方法,通过统计单词在文本中出现频次表征文本语义,忽略单词顺序和语法结构
BoW步骤:构建词表(所有文本中提取唯一单词,每个单词分配唯一索引),向量化(每个文本统计每个单词出现次,生成与词表等长的向量)
例:1:
词表:[天气,雪,股票,美元] ----> 文本:天气 雪 雪 美元 = [1,2,0,1]
例子2:

可把BoW视为文各单词的独热编码one-hot-encoded向量之和
用Scikit Learn库实现BoW:
from sklearn.feature_extraction.text import CountVectorizer
vectorizer = CountVectorizer()
corpus = [
'I like hot dogs.',
'The dog ran fast.',
'Its hot outside.',
]vectorizer.fit_transform(corpus)
vectorizer.transform(['My dog likes hot dogs on a hot day.']).toarray()
输出:
array([[1, 1, 0, 2, 0, 0, 0, 0, 0]], dtype=int64)
生成BoW向量的函数:
vocab_size = len(vocab)
def to_bow(text,bow_vocab_size=vocab_size):
res = torch.zeros(bow_vocab_size,dtype=torch.float32)
for i in encode(text):
if i<bow_vocab_size:
res[i] += 1
return res
print(to_bow(train_dataset[0][1]))
结果:tensor([2., 1., 2., ..., 0., 0., 0.])
词表大小:默认全局vocab_size(太大影响性能),优化:限制为高频词(取前1w个词),可提升计算效率但轻微降低准确率;要逐步降低vs值观察准确率变化再调整
训练BoW分类器:数据转换(bowify()将文本索引序列转成词袋向量),数据加载器配置(PyTorch DataLoader设置collate_n=fn=bowify,自动批量生成BoW表示)
from torch.utils.data import DataLoader
import numpy as np
# this collate function gets list of batch_size tuples, and needs to # return a pair of label-feature tensors for the whole minibatch
def bowify(b):
return (
torch.LongTensor([t[0]-1 for t in b]),
torch.stack([to_bow(t[1]) for t in b])
)
train_loader = DataLoader(train_dataset, batch_size=16, collate_fn=bowify, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=16, collate_fn=bowify, shuffle=True)
定义BoW分类网络:输入向量维度(词表大小),输出维度(类别数,4),激活函数用LogSoftmax()
net = torch.nn.Sequential(torch.nn.Linear(vocab_size,4),torch.nn.LogSoftmax(dim=1))
测试训练一个周期(epoch_size限制步数),按report_freq指定频率报告累积准确率:
def train_epoch(net,dataloader,lr=0.01,optimizer=None,loss_fn = torch.nn.NLLLoss(),epoch_size=None, report_freq=200):
optimizer = optimizer or torch.optim.Adam(net.parameters(),lr=lr)
net.train()
total_loss,acc,count,i = 0,0,0,0
for labels,features in dataloader:
optimizer.zero_grad()
out = net(features)
loss = loss_fn(out,labels) #cross_entropy(out,labels)
loss.backward()
optimizer.step()
total_loss+=loss
_,predicted = torch.max(out,1)
acc+=(predicted==labels).sum()
count+=len(labels)
i+=1
if i%report_freq==0:
print(f"{count}: acc={acc.item()/count}")
if epoch_size and count>epoch_size:
break
return total_loss.item()/count, acc.item()/count
train_epoch(net,train_loader,epoch_size=15000)
输出:(0.026090790722161722, 0.8620069296375267)
N-Gram模型(BiGrams, TriGrams,etc):BoW不能捕捉多词组合(hotdog不等hot dog),引入N-Gram解决
BiGram二元组:相邻俩词组合(hot dog)
TriGram三元组:三个词(hot dog )
N-Gram:连续N个词序列
代码:
bigram_vectorizer = CountVectorizer(ngram_range=(1, 2), token_pattern=r'\b\w+\b', min_df=1)
corpus = [
'I like hot dogs.',
'The dog ran fast.',
'Its hot outside.',
]bigram_vectorizer.fit_transform(corpus)
print("Vocabulary:\n",bigram_vectorizer.vocabulary_)
bigram_vectorizer.transform(['My dog likes hot dogs on a hot day.']).toarray()
词汇:
{'i': 7, 'like': 11, 'hot': 4, 'dogs': 2, 'i like': 8, 'like hot': 12, 'hot dogs': 5, 'the': 16, 'dog': 0, 'ran': 14, 'fast': 3, 'the dog': 17, 'dog ran': 1, 'ran fast': 15, 'its': 9, 'outside': 13, 'its hot': 10, 'hot outside': 6}
输出:
array([[1, 0, 1, 0, 2, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]],
dtype=int64)
N-Gram方法缺点:词表规模膨胀,实际应用结合降维技术(词嵌入,下节讨论)优化
在ASNews里用NGram要构建专用NGram词表:
counter = collections.Counter()for (label, line) in train_dataset:
l = tokenizer(line)
counter.update(torchtext.data.utils.ngrams_iterator(l,ngrams=2))
bi_vocab = torchtext.vocab.vocab(counter, min_freq=1)
print("Bigram vocabulary length = ",len(bi_vocab))
N-Gram分类器优化:用相同代码训练分类器->内存效率低,可以用嵌入方法训练二元分类器
(可用仅保留次数超过设定阈值的NGram,设置min_freq参数=max值来过滤低频组合,降低词表维度)
词频-逆文档频率(TF-IDF):BoW里所有词出现权重一样,但高频词(的,在etc)对分类重要性低
TF-IDF = BoW改进(用浮点数值,不是0/1,表示词的重要性,权重与词在语料中的分布相关)
公式:
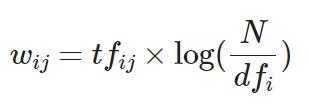
tfij =
N =
dfi =
下面还有一段等DeepSeek翻译
用Scikit Learn创建TF-IDF文本矢量化:
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer(ngram_range=(1,2))v
ectorizer.fit_transform(corpus)
vectorizer.transform(['My dog likes hot dogs on a hot day.']).toarray()
结果:
array([[0.43381609, 0. , 0.43381609, 0. , 0.65985664,
0.43381609, 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. ]])
扩展阅读:
-
TensorFlow文本表示