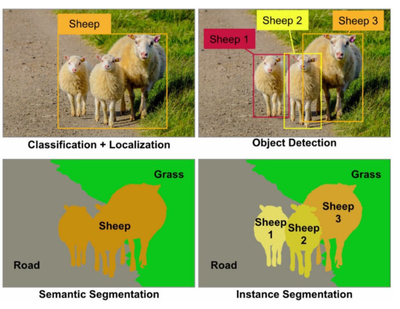
图像分隔:边界框 + 精确物体定位;像素级分类(每个像素预测所属类,背景也是类),有两种类型
-
语义分隔:只区分像素类别(所有羊 = 羊)
-
实例分割:区分同类物体的不同实例(10只羊分别标记不同个体)
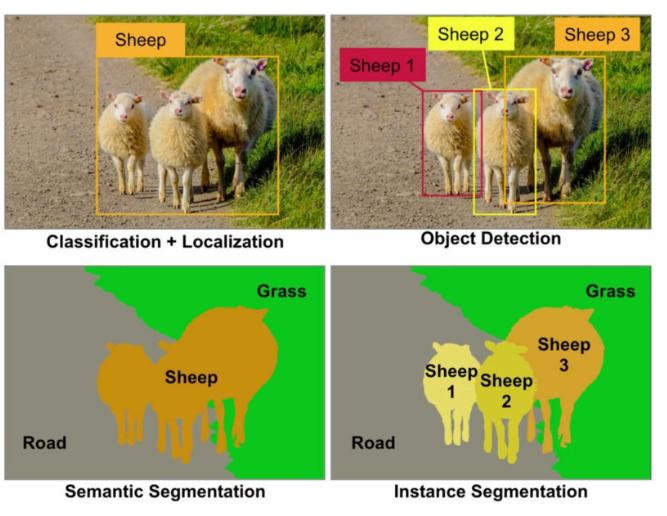
分隔网络架构:编码器(提取输入图像特征),解码器(特征转掩码图像,尺寸一致,通道数=类别数)
代码:
import torch
import torchvision
import matplotlib.pyplot as plt
from torchvision import transforms
from torch import nn
from torch import optim
from tqdm import tqdm
import numpy as npimport torch.nn.functional as F
from skimage.io import imread
from skimage.transform import resize
import ostorch.manual_seed(42)np.random.seed(42)
device = 'cuda:0' if torch.cuda.is_available() else 'cpu'train_size = 0.9
lr = 1e-3
weight_decay = 1e-6
batch_size = 32
epochs = 30
PH2皮肤镜图像库(200张,三类:典型痣,非典型痣,黑色素瘤;都带病灶掩码):
#!apt-get install rar!wget https://www.dropbox.com/s/k88qukc20ljnbuo/PH2Dataset.rar
!unrar x -Y PH2Dataset.rar
图像调整256x256,按比例划分训练集和测试集(函数返回两个集,都有原图+痣区域掩码):
def load_dataset(train_part, root='PH2Dataset'):
images = []
masks = []
for root, dirs, files in os.walk(os.path.join(root, 'PH2 Dataset images')):
if root.endswith('_Dermoscopic_Image'):
images.append(imread(os.path.join(root, files[0])))
if root.endswith('_lesion'):
masks.append(imread(os.path.join(root, files[0])))
size = (256, 256)
images = torch.permute(torch.FloatTensor(np.array([resize(image, size, mode='constant', anti_aliasing=True,) for image in images])), (0, 3, 1, 2))
masks = torch.FloatTensor(np.array([resize(mask, size, mode='constant', anti_aliasing=False) > 0.5 for mask in masks])).unsqueeze(1)
indices = np.random.permutation(range(len(images)))
train_part = int(train_part * len(images))
train_ind = indices[:train_part]
test_ind = indices[train_part:]
train_dataset = (images[train_ind, :, :, :], masks[train_ind, :, :, :])
test_dataset = (images[test_ind, :, :, :], masks[test_ind, :, :, :])
return train_dataset, test_dataset
train_dataset, test_dataset = load_dataset(train_size)
绘图:
def plotn(n, data, only_mask=False):
images, masks = data[0], data[1]
fig, ax = plt.subplots(1, n)
fig1, ax1 = plt.subplots(1, n)
for i, (img, mask) in enumerate(zip(images, masks)):
if i == n:
break
if not only_mask:
ax[i].imshow(torch.permute(img, (1, 2, 0)))
else:
ax[i].imshow(img[0])
ax1[i].imshow(mask[0])
ax[i].axis('off')
ax1[i].axis('off')
plt.show()
plotn(5, train_dataset)
把数据喂给神经网络:
train_dataloader = torch.utils.data.DataLoader(list(zip(train_dataset[0], train_dataset[1])), batch_size=batch_size, shuffle=True)
test_dataloader = torch.utils.data.DataLoader(list(zip(test_dataset[0], test_dataset[1])), batch_size=1, shuffle=False)
dataloaders = (train_dataloader, test_dataloader)
SegNet:编码器(标准CNN=卷积+池化),解码器(反卷积CNN=卷积+上采样),用批量归一化稳定深层网络训练
代码:
class SegNet(nn.Module):
def __init__(self):
super().__init__()
self.enc_conv0 = nn.Conv2d(in_channels=3, out_channels=16, kernel_size=(3,3), padding=1)
self.act0 = nn.ReLU()
self.bn0 = nn.BatchNorm2d(16)
self.pool0 = nn.MaxPool2d(kernel_size=(2,2))
self.enc_conv1 = nn.Conv2d(in_channels=16, out_channels=32, kernel_size=(3,3), padding=1)
self.act1 = nn.ReLU()
self.bn1 = nn.BatchNorm2d(32)
self.pool1 = nn.MaxPool2d(kernel_size=(2,2))
self.enc_conv2 = nn.Conv2d(in_channels=32, out_channels=64, kernel_size=(3,3), padding=1)
self.act2 = nn.ReLU()
self.bn2 = nn.BatchNorm2d(64)
self.pool2 = nn.MaxPool2d(kernel_size=(2,2))
self.enc_conv3 = nn.Conv2d(in_channels=64, out_channels=128, kernel_size=(3,3), padding=1)
self.act3 = nn.ReLU()
self.bn3 = nn.BatchNorm2d(128)
self.pool3 = nn.MaxPool2d(kernel_size=(2,2))
self.bottleneck_conv = nn.Conv2d(in_channels=128, out_channels=256, kernel_size=(3,3), padding=1)
self.upsample0 = nn.UpsamplingBilinear2d(scale_factor=2)
self.dec_conv0 = nn.Conv2d(in_channels=256, out_channels=128, kernel_size=(3,3), padding=1)
self.dec_act0 = nn.ReLU()
self.dec_bn0 = nn.BatchNorm2d(128)
self.upsample1 = nn.UpsamplingBilinear2d(scale_factor=2)
self.dec_conv1 = nn.Conv2d(in_channels=128, out_channels=64, kernel_size=(3,3), padding=1)
self.dec_act1 = nn.ReLU()
self.dec_bn1 = nn.BatchNorm2d(64)
self.upsample2 = nn.UpsamplingBilinear2d(scale_factor=2)
self.dec_conv2 = nn.Conv2d(in_channels=64, out_channels=32, kernel_size=(3,3), padding=1)
self.dec_act2 = nn.ReLU()
self.dec_bn2 = nn.BatchNorm2d(32)
self.upsample3 = nn.UpsamplingBilinear2d(scale_factor=2)
self.dec_conv3 = nn.Conv2d(in_channels=32, out_channels=1, kernel_size=(1,1))
self.sigmoid = nn.Sigmoid()
def forward(self, x):
e0 = self.pool0(self.bn0(self.act0(self.enc_conv0(x))))
e1 = self.pool1(self.bn1(self.act1(self.enc_conv1(e0))))
e2 = self.pool2(self.bn2(self.act2(self.enc_conv2(e1))))
e3 = self.pool3(self.bn3(self.act3(self.enc_conv3(e2))))
b = self.bottleneck_conv(e3)
d0 = self.dec_bn0(self.dec_act0(self.dec_conv0(self.upsample0(b))))
d1 = self.dec_bn1(self.dec_act1(self.dec_conv1(self.upsample1(d0))))
d2 = self.dec_bn2(self.dec_act2(self.dec_conv2(self.upsample2(d1))))
d3 = self.sigmoid(self.dec_conv3(self.upsample3(d2)))
return d3
分隔任务损失函数:
分类损失(用交叉熵损失,逐个像素计算类别概率差异),二值掩码(若掩码为二值就用二院交叉熵损失BCE),与传统自编码器相比(传统用MSE)分割更适应分类任务
model = SegNet().to(device)optimizer = optim.Adam(model.parameters(), lr=lr, weight_decay=weight_decay)
loss_fn = nn.BCEWithLogitsLoss()
训练循环:
def train(dataloaders, model, loss_fn, optimizer, epochs, device):
tqdm_iter = tqdm(range(epochs))
train_dataloader, test_dataloader = dataloaders[0], dataloaders[1]
for epoch in tqdm_iter:
model.train()
train_loss = 0.0
test_loss = 0.0
for batch in train_dataloader:
imgs, labels = batch
imgs = imgs.to(device)
labels = labels.to(device)
preds = model(imgs)
loss = loss_fn(preds, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss += loss.item()
model.eval()
with torch.no_grad():
for batch in test_dataloader:
imgs, labels = batch
imgs = imgs.to(device)
labels = labels.to(device)
preds = model(imgs)
loss = loss_fn(preds, labels)
test_loss += loss.item()
train_loss /= len(train_dataloader)
test_loss /= len(test_dataloader)
tqdm_dct = {'train loss:': train_loss, 'test loss:': test_loss}
tqdm_iter.set_postfix(tqdm_dct, refresh=True)
tqdm_iter.refresh()
train(dataloaders, model, loss_fn, optimizer, epochs, device)
绘图:目标掩码,预测掩码
model.eval()predictions = []image_mask = []plots = 5images, masks = test_dataset[0], test_dataset[1]for i, (img, mask) in enumerate(zip(images, masks)):
if i == plots:
break
img = img.to(device).unsqueeze(0)
predictions.append((model(img).detach().cpu()[0] > 0.5).float())
image_mask.append(mask)
plotn(plots, (predictions, image_mask), only_mask=True)

像素准确率:正确分类的像素百分比,是直观指标
U-Net架构:SsetNet编码器下采样丢失空间细节,解码重建精度受限,所以用U-Net
跳跃连接:编码器每层的特征图和解码器对应层连接,保留原始细节
U-Net编码器灵活,基础板用CNN,可替换成ResNet-50增强特征提取
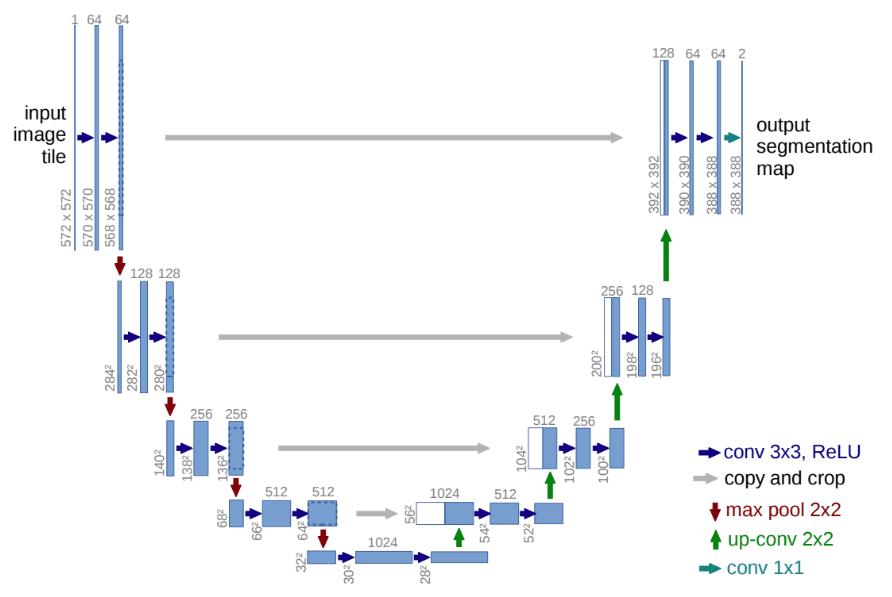
代码:
class UNet(nn.Module):
def __init__(self):
super().__init__()
self.enc_conv0 = nn.Conv2d(in_channels=3, out_channels=16, kernel_size=(3,3), padding=1)
self.act0 = nn.ReLU()
self.bn0 = nn.BatchNorm2d(16)
self.pool0 = nn.MaxPool2d(kernel_size=(2,2))
self.enc_conv1 = nn.Conv2d(in_channels=16, out_channels=32, kernel_size=(3,3), padding=1)
self.act1 = nn.ReLU()
self.bn1 = nn.BatchNorm2d(32)
self.pool1 = nn.MaxPool2d(kernel_size=(2,2))
self.enc_conv2 = nn.Conv2d(in_channels=32, out_channels=64, kernel_size=(3,3), padding=1)
self.act2 = nn.ReLU()
self.bn2 = nn.BatchNorm2d(64)
self.pool2 = nn.MaxPool2d(kernel_size=(2,2))
self.enc_conv3 = nn.Conv2d(in_channels=64, out_channels=128, kernel_size=(3,3), padding=1)
self.act3 = nn.ReLU()
self.bn3 = nn.BatchNorm2d(128)
self.pool3 = nn.MaxPool2d(kernel_size=(2,2))
self.bottleneck_conv = nn.Conv2d(in_channels=128, out_channels=256, kernel_size=(3,3), padding=1)
self.upsample0 = nn.UpsamplingBilinear2d(scale_factor=2)
self.dec_conv0 = nn.Conv2d(in_channels=384, out_channels=128, kernel_size=(3,3), padding=1)
self.dec_act0 = nn.ReLU()
self.dec_bn0 = nn.BatchNorm2d(128)
self.upsample1 = nn.UpsamplingBilinear2d(scale_factor=2)
self.dec_conv1 = nn.Conv2d(in_channels=192, out_channels=64, kernel_size=(3,3), padding=1)
self.dec_act1 = nn.ReLU()
self.dec_bn1 = nn.BatchNorm2d(64)
self.upsample2 = nn.UpsamplingBilinear2d(scale_factor=2)
self.dec_conv2 = nn.Conv2d(in_channels=96, out_channels=32, kernel_size=(3,3), padding=1)
self.dec_act2 = nn.ReLU()
self.dec_bn2 = nn.BatchNorm2d(32)
self.upsample3 = nn.UpsamplingBilinear2d(scale_factor=2)
self.dec_conv3 = nn.Conv2d(in_channels=48, out_channels=1, kernel_size=(1,1))
self.sigmoid = nn.Sigmoid()
def forward(self, x):
e0 = self.pool0(self.bn0(self.act0(self.enc_conv0(x))))
e1 = self.pool1(self.bn1(self.act1(self.enc_conv1(e0))))
e2 = self.pool2(self.bn2(self.act2(self.enc_conv2(e1))))
e3 = self.pool3(self.bn3(self.act3(self.enc_conv3(e2))))
cat0 = self.bn0(self.act0(self.enc_conv0(x)))
cat1 = self.bn1(self.act1(self.enc_conv1(e0)))
cat2 = self.bn2(self.act2(self.enc_conv2(e1)))
cat3 = self.bn3(self.act3(self.enc_conv3(e2)))
b = self.bottleneck_conv(e3)
d0 = self.dec_bn0(self.dec_act0(self.dec_conv0(torch.cat((self.upsample0(b), cat3), dim=1))))
d1 = self.dec_bn1(self.dec_act1(self.dec_conv1(torch.cat((self.upsample1(d0), cat2), dim=1))))
d2 = self.dec_bn2(self.dec_act2(self.dec_conv2(torch.cat((self.upsample2(d1), cat1), dim=1))))
d3 = self.sigmoid(self.dec_conv3(torch.cat((self.upsample3(d2), cat0), dim=1)))
return d3
model = UNet().to(device)optimizer = optim.Adam(model.parameters(), lr=lr, weight_decay=weight_decay)
loss_fn = nn.BCEWithLogitsLoss()
train(dataloaders, model, loss_fn, optimizer, epochs, device)
model.eval()predictions = []image_mask = []plots = 5images, masks = test_dataset[0], test_dataset[1]for i, (img, mask) in enumerate(zip(images, masks)):
if i == plots:
break
img = img.to(device).unsqueeze(0)
predictions.append((model(img).detach().cpu()[0] > 0.5).float())
image_mask.append(mask)
plotn(plots, (predictions, image_mask), only_mask=True)

扩展阅读:
-
TensorFlow语义分隔模型实现与性能分析
-
分割人体图像实验