
加载图片:
!mkdir -p images
!curl https://cdn.pixabay.com/photo/2016/05/18/00/27/franz-marc-1399594_960_720.jpg > images/style.jpg
{kind=link}
!curl https://upload.wikimedia.org/wikipedia/commons/thumb/b/bd/Golden_tabby_and_white_kitten_n01.jpg/1280px-Golden_tabby_and_white_kitten_n01.jpg > images/image.jpg
{kind=link}
内部数据结果:
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 210k 100 210k 0 0 2670k 0 --:--:-- --:--:-- --:--:-- 2670k
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 131k 100 131k 0 0 459k 0 --:--:-- --:--:-- --:--:-- 459k
import cv2
import numpy as np
import matplotlib.pyplot as plt
import matplotlib
import tensorflow as tf
from tensorflow.keras.applications.vgg16 import preprocess_input
import IPython.display as display
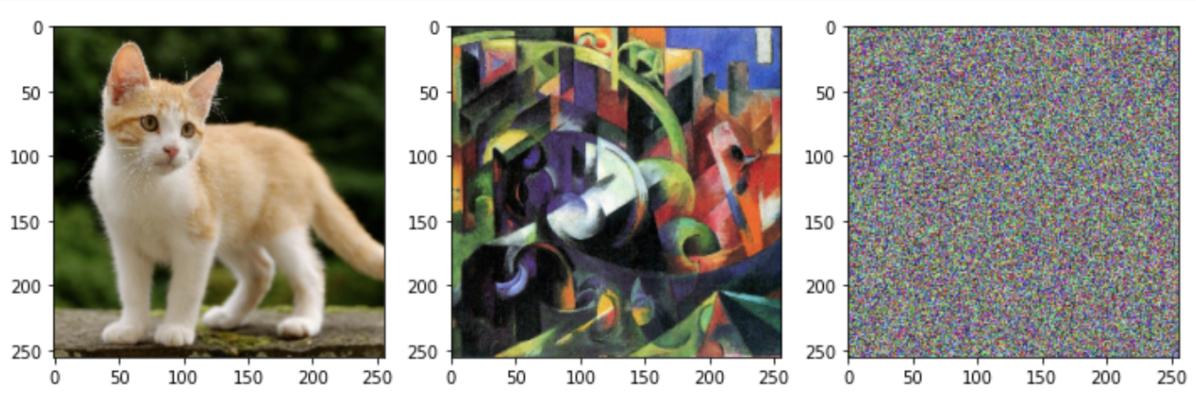
加载图片+重置大小512x512,生成Img_result(当做随机数组)
img_size = 256
def load_image(fn):
x = cv2.imread(fn)
return cv2.cvtColor(x, cv2.COLOR_BGR2RGB)
img_style = load_image('images/style.jpg')
img_content = load_image('images/image.jpg')
img_content = img_content[:,200:200+857,:]
img_content = cv2.resize(img_content,(img_size,img_size))
img_style = img_style[:,200:200+671,:]
img_style = cv2.resize(img_style,(img_size,img_size))
img_result = np.random.uniform(size=(img_size,img_size,3))
matplotlib.rcParams['figure.figsize'] = (12, 12)
matplotlib.rcParams['axes.grid'] = False
fig,ax = plt.subplots(1,3)ax[0].imshow(img_content)
ax[1].imshow(img_style)
ax[2].imshow((255*img_result).astype(int))
plt.show()
计算风格损失和内容损失要在CNN提取的特征空间上操作,选不同CNN架构简化实现(比如在ImageNet预训练的VGG-19作特征提取器):
vgg = tf.keras.applications.VGG16(include_top=False, weights='imagenet')
vgg.trainable = False
查看模型架构信息:
vgg.summary()
结果:略
定义提取VGG中间特征的函数:
def layer_extractor(layers):
outputs = [vgg.get_layer(x).output for x in layers]
model = tf.keras.Model([vgg.input],outputs)
return model
内容损失:衡量当前图x与原图的相似度,计算CNN中间特征层的平方误差
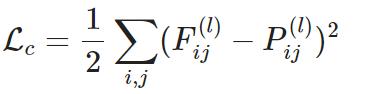
F(l)和P(l)都是层l的特征
代码:
content_layers = ['block4_conv2']
content_extractor = layer_extractor(content_layers)
content_target = content_extractor(preprocess_input(tf.expand_dims(img_content,axis=0)))
def content_loss(img):
z = content_extractor(preprocess_input(tf.expand_dims(255*img,axis=0)))
return 0.5*tf.reduce_sum((z-content_target)**2)
风格迁移的优化过程:
从随机噪声图开始,用TensorFlow优化器调整图像,逐步最小化内容损失和风格损失
好处:用的GPU+TensorFlow,大规模图+深层网络时最好用
代码:
img = tf.Variable(img_result)opt = tf.optimizers.Adam(learning_rate=0.002, beta_1=0.99, epsilon=1e-1)
clip = lambda x : tf.clip_by_value(x,clip_value_min=0,clip_value_max=1)
def optimize(img,loss_fn):
with tf.GradientTape() as tape:
loss = loss_fn(img)
grad = tape.gradient(loss,img)
opt.apply_gradients([(grad,img)])
#img.assign(tf.clip_by_value(img,clip_value_min=0,clip_value_max=1))
def train(img,loss_fn,epochs=10,steps_per_epoch=100):
for _ in range(epochs):
display.clear_output(wait=True)
plt.imshow((255*clip(img)).numpy().astype(int))
plt.show()
for _ in range(steps_per_epoch):
optimize(img,loss_fn=loss_fn)
train(img,content_loss)

风格损失:
不直接比较特征,比较他们的Gram矩阵(协方差矩阵,表示不同滤波器/特征之间的相关性);加权求和+不同层(VGG多个卷积层)的Gram差异来计算
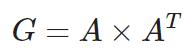
总风格损失 = 内容损失+风格损失:
def gram_matrix(x):
result = tf.linalg.einsum('bijc,bijd->bcd', x, x)
input_shape = tf.shape(x)
num_locations = tf.cast(input_shape[1]*input_shape[2], tf.float32)
return result/(num_locations)
style_layers = ['block1_conv1','block2_conv1','block3_conv1','block4_conv1']
def style_extractor(img):
return [gram_matrix(x) for x in layer_extractor(style_layers)(img)]
style_target = style_extractor(preprocess_input(tf.expand_dims(img_style,axis=0)))
def style_loss(img):
z = style_extractor(preprocess_input(tf.expand_dims(255*img,axis=0)))
loss = tf.add_n([tf.reduce_mean((x-target)**2)
for x,target in zip(z,style_target)])
return loss / len(style_layers)
定义total_loss(),计算总损失,然后优化:
def total_loss(img):
return 2*content_loss(img)+style_loss(img)
img.assign(img_result)
train(img,loss_fn=total_loss)
结果:

总变差损失:最小化相邻像素差异,减少生成图噪声,提升平滑性
从原始内容图像开始优化(不是从随机噪声开始),保留更多内容细节
添加轻微噪声 -> 平衡内容保留+风格迁移的灵活性
代码:
def variation_loss(img):
img = tf.cast(img,tf.float32)
x_var = img[ :, 1:, :] - img[ :, :-1, :]
y_var = img[ 1:, :, :] - img[ :-1, :, :]
return tf.reduce_sum(tf.abs(x_var)) + tf.reduce_sum(tf.abs(y_var))
def total_loss_var(img):
return content_loss(img)+150*style_loss(img)+30*variation_loss(img)
img.assign(clip(np.random.normal(-0.3,0.3,size=img_content.shape)+img_content/255.0))
train(img,loss_fn=total_loss_var)

cv2.imwrite('result.jpg',(img.numpy()[:,:,::-1]*255))
(256, 256, 3)
输出:true
扩展阅读:
-
TensorFlow的GAN实践
-
用DCGAN才CIFAR-10数据集的特定类别生成彩图
-
风格迁移
-
Keras在风格迁移中的实践
-
多层同时优化实验