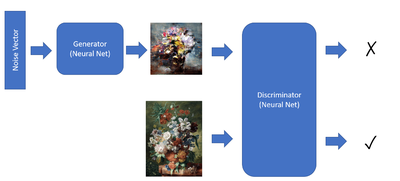
GAN原理:以生成与训练数据集相似不重复的图为目标,有两个对抗训练的神经网络(生成器,判别器)
生成器:输入(随机向量,如正态分布采样噪声),输出(合成图,模拟真实数据分布)
判别器:输入(真实图像或者生成器假图),输出(概率值)
训练过程:用生成器生成逼真图像欺骗判别器,用判别器学习区分真图假图(两个器不断对抗优化,最终生成图与真实数据分布高度接近)
import torch
import torchvision
import matplotlib.pyplot as plt
from torchvision import transforms
from torch import nn
from torch import optim
from tqdm import tqdm
import numpy as np
import torch.nn.functional as Ftorch.manual_seed(42)np.random.seed(42)
device = 'cuda:0' if torch.cuda.is_available() else 'cpu'
train_size = 1.0
lr = 2e-4
weight_decay = 8e-9
beta1 = 0.5
beta2 = 0.999
batch_size = 256
epochs = 100
plot_every = 10
生成器:接收随机向量,生成目标图像,跟自编码器生成端(解码器)类似;
用全连接神经网络(线性网络)+ MINST + 生成器:
class Generator(nn.Module):
def __init__(self):
super().__init__()
self.linear1 = nn.Linear(100, 256)
self.bn1 = nn.BatchNorm1d(256, momentum=0.2)
self.linear2 = nn.Linear(256, 512)
self.bn2 = nn.BatchNorm1d(512, momentum=0.2)
self.linear3 = nn.Linear(512, 1024)
self.bn3 = nn.BatchNorm1d(1024, momentum=0.2)
self.linear4 = nn.Linear(1024, 784)
self.tanh = nn.Tanh()
self.leaky_relu = nn.LeakyReLU(0.2)
def forward(self, input):
hidden1 = self.leaky_relu(self.bn1(self.linear1(input)))
hidden2 = self.leaky_relu(self.bn2(self.linear2(hidden1)))
hidden3 = self.leaky_relu(self.bn3(self.linear3(hidden2)))
generated = self.tanh(self.linear4(hidden3)).view(input.shape[0], 1, 28, 28)
return generated
生成器设计要注意的:
-
激活函数:LeakyReLU(负区间保留微小斜率0.2,避免梯度消失)=== 缓解神经元死亡,最后一层用Tanh(输出限制在[-1,1],匹配归一化后的图数据) ===控制输出范围
-
稳定训练:BatchNOrm1D归一化中间层输出,加速收敛,防止梯度异常 === 稳定训练动态
判别器:
class Discriminator(nn.Module):
def __init__(self):
super().__init__()
self.linear1 = nn.Linear(784, 512)
self.linear2 = nn.Linear(512, 256)
self.linear3 = nn.Linear(256, 1)
self.leaky_relu = nn.LeakyReLU(0.2)
self.sigmoid = nn.Sigmoid()
def forward(self, input):
input = input.view(input.shape[0], -1)
hidden1 = self.leaky_relu(self.linear1(input))
hidden2 = self.leaky_relu(self.linear2(hidden1))
classififed = self.sigmoid(self.linear3(hidden2))
return classififed
加载数据集:
def mnist(train_part, transform=None):
dataset = torchvision.datasets.MNIST('.', download=True, transform=transform)
train_part = int(train_part * len(dataset))
train_dataset, test_dataset = torch.utils.data.random_split(dataset, [train_part, len(dataset) - train_part])
return train_dataset, test_dataset
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=0.5, std=0.5)])
train_dataset, test_dataset = mnist(train_size, transform)
train_dataloader = torch.utils.data.DataLoader(train_dataset, drop_last=True, batch_size=batch_size, shuffle=True)
dataloaders = (train_dataloader, )
GAN训练:
循环步骤,每轮有两阶段:
-
生成器训练:输入(随机噪声向量batch_size=100,目标标签),目标标签(全1向量(形状(bs,1),欺骗判别器)),损失计算(冻结判别器参数 -> 生成假图 -> 计算判别器输出与真实标签的损失,如BCE loss);优化(只更新生成器参数)
-
判别器训练:输入分成真图(标签=全1向量)+生成器假图(标签=全0向量);损失计算(判别器总损失=(判别假图的损失 + 判别真图的损失) / 2),优化(只更新判别器参数)
公式:
生成器损失 = Loss_G = BCE(D(G(z)), 1)
判别器损失 = Loss_G = [BCE(D(G(z), 0)) + BCE(D(x_real), 1)] / 2
代码:
def plotn(n, generator, device):
generator.eval()
noise = torch.FloatTensor(np.random.normal(0, 1, (n, 100))).to(device)
imgs = generator(noise).detach().cpu()
fig, ax = plt.subplots(1, n)
for i, im in enumerate(imgs):
ax[i].imshow(im[0])
plt.show()
def train_gan(dataloaders, models, optimizers, loss_fn, epochs, plot_every, device):
tqdm_iter = tqdm(range(epochs))
train_dataloader = dataloaders[0]
gen, disc = models[0], models[1]
optim_gen, optim_disc = optimizers[0], optimizers[1]
for epoch in tqdm_iter:
gen.train()
disc.train()
train_gen_loss = 0.0
train_disc_loss = 0.0
test_gen_loss = 0.0
test_disc_loss = 0.0
for batch in train_dataloader:
imgs, _ = batch
imgs = imgs.to(device)
disc.eval()
gen.zero_grad()
noise = torch.FloatTensor(np.random.normal(0.0, 1.0, (imgs.shape[0], 100))).to(device)
real_labels = torch.ones((imgs.shape[0], 1)).to(device)
fake_labels = torch.zeros((imgs.shape[0], 1)).to(device)
generated = gen(noise)
disc_preds = disc(generated)
g_loss = loss_fn(disc_preds, real_labels)
g_loss.backward()
optim_gen.step()
disc.train()
disc.zero_grad()
disc_real = disc(imgs)
disc_real_loss = loss_fn(disc_real, real_labels)
disc_fake = disc(generated.detach())
disc_fake_loss = loss_fn(disc_fake, fake_labels)
d_loss = (disc_real_loss + disc_fake_loss) / 2.0
d_loss.backward()
optim_disc.step()
train_gen_loss += g_loss.item()
train_disc_loss += d_loss.item()
train_gen_loss /= len(train_dataloader)
train_disc_loss /= len(train_dataloader)
if epoch % plot_every == 0 or epoch == epochs - 1:
plotn(5, gen, device)
tqdm_dct = {'generator loss:': train_gen_loss, 'discriminator loss:': train_disc_loss}
tqdm_iter.set_postfix(tqdm_dct, refresh=True)
tqdm_iter.refresh()
generator = Generator().to(device)
discriminator = Discriminator().to(device)optimizer_generator = optim.Adam(generator.parameters(), lr=lr, weight_decay=weight_decay, betas=(beta1, beta2))
optimizer_discriminator = optim.Adam(discriminator.parameters(), lr=lr, weight_decay=weight_decay, betas=(beta1, beta2))
loss_fn = nn.BCELoss()
models = (generator, discriminator)optimizers = (optimizer_generator, optimizer_discriminator)
训练:
train_gan(dataloaders, models, optimizers, loss_fn, epochs, plot_every, device)

DCGAN:深度卷积生成对抗网络
将GAN的全连接层换成卷积层,生成器用转置卷积(Conv2DTranspose)逐步上采样(从噪声向量生图),判别器(用普通卷积层逐步下采样(从图输出判别概率))
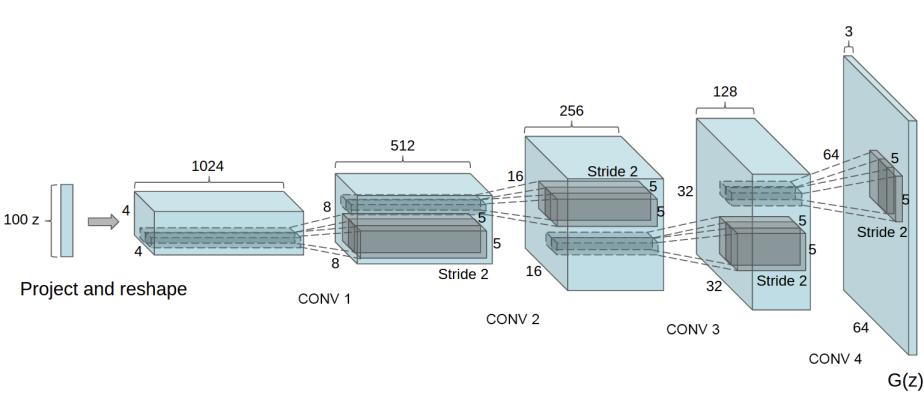
class DCGenerator(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.ConvTranspose2d(100, 256, kernel_size=(3, 3), stride=(2, 2), bias=False)
self.bn1 = nn.BatchNorm2d(256)
self.conv2 = nn.ConvTranspose2d(256, 128, kernel_size=(3, 3), stride=(2, 2), bias=False)
self.bn2 = nn.BatchNorm2d(128)
self.conv3 = nn.ConvTranspose2d(128, 64, kernel_size=(3, 3), stride=(2, 2), bias=False)
self.bn3 = nn.BatchNorm2d(64)
self.conv4 = nn.ConvTranspose2d(64, 1, kernel_size=(3, 3), stride=(2, 2), padding=(2, 2), output_padding=(1, 1), bias=False)
self.tanh = nn.Tanh()
self.relu = nn.ReLU()
def forward(self, input):
hidden1 = self.relu(self.bn1(self.conv1(input)))
hidden2 = self.relu(self.bn2(self.conv2(hidden1)))
hidden3 = self.relu(self.bn3(self.conv3(hidden2)))
generated = self.tanh(self.conv4(hidden3)).view(input.shape[0], 1, 28, 28)
return generated
class DCDiscriminator(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
self.conv2 = nn.Conv2d(64, 128, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
self.bn2 = nn.BatchNorm2d(128)
self.conv3 = nn.Conv2d(128, 256, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
self.bn3 = nn.BatchNorm2d(256)
self.conv4 = nn.Conv2d(256, 1, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
self.leaky_relu = nn.LeakyReLU(0.2)
self.sigmoid = nn.Sigmoid()
def forward(self, input):
hidden1 = self.leaky_relu(self.conv1(input))
hidden2 = self.leaky_relu(self.bn2(self.conv2(hidden1)))
hidden3 = self.leaky_relu(self.bn3(self.conv3(hidden2)))
classified = self.sigmoid(self.conv4(hidden3)).view(input.shape[0], -1)
return classified
def weights_init(model):
classname = model.__class__.__name__
if classname.find('Conv') != -1:
nn.init.normal_(model.weight.data, 0.0, 0.02)
elif classname.find('BatchNorm') != -1:
nn.init.normal_(model.weight.data, 1.0, 0.02)
nn.init.constant_(model.bias.data, 0)
transform = transforms.Compose([
transforms.ToTensor(),])
train_dataset, test_dataset = mnist(train_size, transform)
train_dataloader = torch.utils.data.DataLoader(train_dataset, drop_last=True, batch_size=batch_size, shuffle=True)
dataloaders = (train_dataloader, )
generator = DCGenerator().to(device)generator.apply(weights_init)
discriminator = DCDiscriminator().to(device)discriminator.apply(weights_init)
optimizer_generator = optim.Adam(generator.parameters(), lr=lr, weight_decay=weight_decay, betas=(beta1, beta2))
optimizer_discriminator = optim.Adam(discriminator.parameters(), lr=lr, weight_decay=weight_decay, betas=(beta1, beta2))
loss_fn = nn.BCELoss()
models = (generator, discriminator)
optimizers = (optimizer_generator, optimizer_discriminator)
def dcplotn(n, generator, device):
generator.eval()
noise = torch.FloatTensor(np.random.normal(0, 1, (n, 100, 1, 1))).to(device)
imgs = generator(noise).detach().cpu()
fig, ax = plt.subplots(1, n)
for i, im in enumerate(imgs):
ax[i].imshow(im[0])
plt.show()
def train_dcgan(dataloaders, models, optimizers, loss_fn, epochs, plot_every, device):
tqdm_iter = tqdm(range(epochs))
train_dataloader = dataloaders[0]
gen, disc = models[0], models[1]
optim_gen, optim_disc = optimizers[0], optimizers[1]
gen.train()
disc.train()
for epoch in tqdm_iter:
train_gen_loss = 0.0
train_disc_loss = 0.0
test_gen_loss = 0.0
test_disc_loss = 0.0
for batch in train_dataloader:
imgs, _ = batch
imgs = imgs.to(device)
imgs = 2.0 * imgs - 1.0
gen.zero_grad()
noise = torch.FloatTensor(np.random.normal(0.0, 1.0, (imgs.shape[0], 100, 1, 1))).to(device)
real_labels = torch.ones((imgs.shape[0], 1)).to(device)
fake_labels = torch.zeros((imgs.shape[0], 1)).to(device)
generated = gen(noise)
disc_preds = disc(generated)
g_loss = loss_fn(disc_preds, real_labels)
g_loss.backward()
optim_gen.step()
disc.zero_grad()
disc_real = disc(imgs)
disc_real_loss = loss_fn(disc_real, real_labels)
disc_fake = disc(generated.detach())
disc_fake_loss = loss_fn(disc_fake, fake_labels)
d_loss = (disc_real_loss + disc_fake_loss) / 2.0
d_loss.backward()
optim_disc.step()
train_gen_loss += g_loss.item()
train_disc_loss += d_loss.item()
train_gen_loss /= len(train_dataloader)
train_disc_loss /= len(train_dataloader)
if epoch % plot_every == 0 or epoch == epochs - 1:
dcplotn(5, gen, device)
tqdm_dct = {'generator loss:': train_gen_loss, 'discriminator loss:': train_disc_loss}
tqdm_iter.set_postfix(tqdm_dct, refresh=True)
tqdm_iter.refresh()
训练:
train_dcgan(dataloaders, models, optimizers, loss_fn, epochs // 2, plot_every // 2, device)

generator.eval()
dcplotn(5, generator, device)

用DCGAN生成的AIGC图:

扩展阅读:
-
TensorFlow的GAN实践
-
用DCGAN才CIFAR-10数据集的特定类别生成彩图
-
风格迁移
-
Keras在风格迁移中的实践
-
TensorFlow在风格迁移中的实践