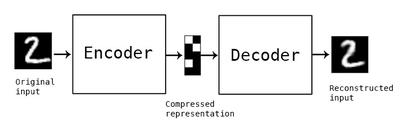
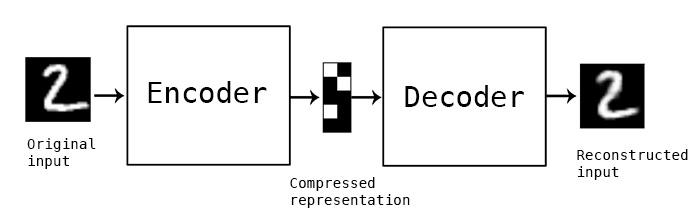
自监督学习:不用标注标签,数据自身生成监督信号
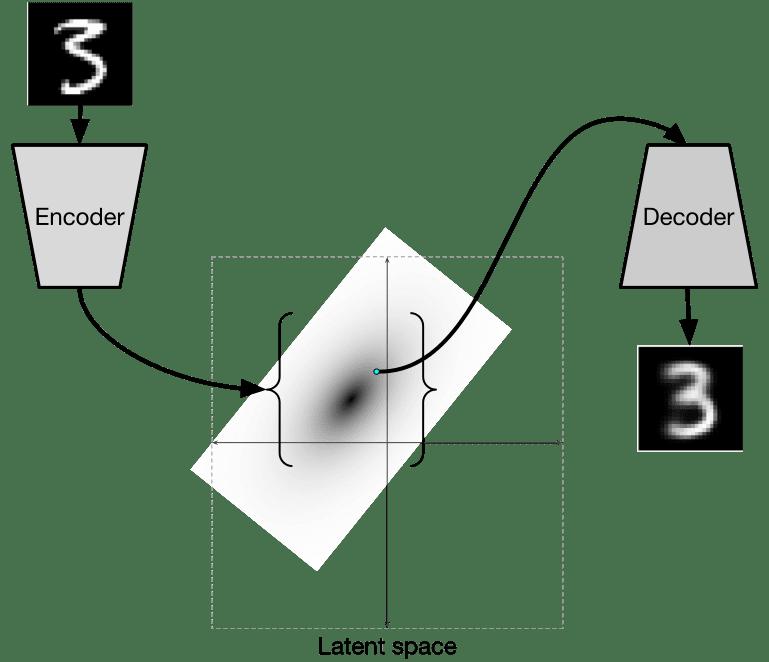
自编码器:编码器(输入图像压缩成低维潜在表示),解码器(潜在表示重建原始图像);不用标注还可以特征服用
训练目标:最小化输入图像和重建图像之间的差异(均方误差);让网络学习数据关键特征生成搞笑潜在表示
import torch
import torchvision
import matplotlib.pyplot as plt
from torchvision import transforms
from torch import nn
from torch import optim
from tqdm import tqdm
import numpy as np
import torch.nn.functional as Ftorch.manual_seed(42)np.random.seed(42)
定义训练参数、检查GPU:
device = 'cuda:0' if torch.cuda.is_available() else 'cpu'
train_size = 0.9
lr = 1e-3
eps = 1e-8
batch_size = 256
epochs = 30
加载MNIST数据集,变换,分离成训练和测试数据集
transform = transforms.Compose([transforms.ToTensor()])
train_dataset, test_dataset = mnist(train_size, transform)
train_dataloader = torch.utils.data.DataLoader(train_dataset, drop_last=True, batch_size=batch_size, shuffle=True)test_dataloader = torch.utils.data.DataLoader(test_dataset, batch_size=1, shuffle=False)dataloaders = (train_dataloader, test_dataloader)
def plotn(n, data, noisy=False, super_res=None):
fig, ax = plt.subplots(1, n)
for i, z in enumerate(data):
if i == n:
break
preprocess = z[0].reshape(1, 28, 28) if z[0].shape[1] == 28 else z[0].reshape(1, 14, 14) if z[0].shape[1] == 14 else z[0]
if super_res is not None:
_transform = transforms.Resize((int(preprocess.shape[1] / super_res), int(preprocess.shape[2] / super_res)))
preprocess = _transform(preprocess)
if noisy:
shapes = list(preprocess.shape)
preprocess += noisify(shapes)
ax[i].imshow(preprocess[0])
plt.show()
def noisify(shapes):
return np.random.normal(loc=0.5, scale=0.3, size=shapes)
plotn(5, train_dataset)
class Encoder(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, 16, kernel_size=(3, 3), padding='same')
self.maxpool1 = nn.MaxPool2d(kernel_size=(2, 2))
self.conv2 = nn.Conv2d(16, 8, kernel_size=(3, 3), padding='same')
self.maxpool2 = nn.MaxPool2d(kernel_size=(2, 2))
self.conv3 = nn.Conv2d(8, 8, kernel_size=(3, 3), padding='same')
self.maxpool3 = nn.MaxPool2d(kernel_size=(2, 2), padding=(1, 1))
self.relu = nn.ReLU()
def forward(self, input):
hidden1 = self.maxpool1(self.relu(self.conv1(input)))
hidden2 = self.maxpool2(self.relu(self.conv2(hidden1)))
encoded = self.maxpool3(self.relu(self.conv3(hidden2)))
return encoded
class Decoder(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(8, 8, kernel_size=(3, 3), padding='same')
self.upsample1 = nn.Upsample(scale_factor=(2, 2))
self.conv2 = nn.Conv2d(8, 8, kernel_size=(3, 3), padding='same')
self.upsample2 = nn.Upsample(scale_factor=(2, 2))
self.conv3 = nn.Conv2d(8, 16, kernel_size=(3, 3))
self.upsample3 = nn.Upsample(scale_factor=(2, 2))
self.conv4 = nn.Conv2d(16, 1, kernel_size=(3, 3), padding='same')
self.relu = nn.ReLU()
self.sigmoid = nn.Sigmoid()
def forward(self, input):
hidden1 = self.upsample1(self.relu(self.conv1(input)))
hidden2 = self.upsample2(self.relu(self.conv2(hidden1)))
hidden3 = self.upsample3(self.relu(self.conv3(hidden2)))
decoded = self.sigmoid(self.conv4(hidden3))
return decoded
class AutoEncoder(nn.Module):
def __init__(self, super_resolution=False):
super().__init__()
if not super_resolution:
self.encoder = Encoder()
else:
self.encoder = SuperResolutionEncoder()
self.decoder = Decoder()
def forward(self, input):
encoded = self.encoder(input)
decoded = self.decoder(encoded)
return decoded
model = AutoEncoder().to(device)
optimizer = optim.Adam(model.parameters(), lr=lr, eps=eps)
loss_fn = nn.BCELoss()
def train(dataloaders, model, loss_fn, optimizer, epochs, device, noisy=None, super_res=None):
tqdm_iter = tqdm(range(epochs))
train_dataloader, test_dataloader = dataloaders[0], dataloaders[1]
for epoch in tqdm_iter:
model.train()
train_loss = 0.0
test_loss = 0.0
for batch in train_dataloader:
imgs, labels = batch
shapes = list(imgs.shape)
if super_res is not None:
shapes[2], shapes[3] = int(shapes[2] / super_res), int(shapes[3] / super_res)
_transform = transforms.Resize((shapes[2], shapes[3]))
imgs_transformed = _transform(imgs)
imgs_transformed = imgs_transformed.to(device)
imgs = imgs.to(device)
labels = labels.to(device)
if noisy is not None:
noisy_tensor = noisy[0]
else:
noisy_tensor = torch.zeros(tuple(shapes)).to(device)
if super_res is None:
imgs_noisy = imgs + noisy_tensor
else:
imgs_noisy = imgs_transformed + noisy_tensor
imgs_noisy = torch.clamp(imgs_noisy, 0., 1.)
preds = model(imgs_noisy)
loss = loss_fn(preds, imgs)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss += loss.item()
model.eval()
with torch.no_grad():
for batch in test_dataloader:
imgs, labels = batch
shapes = list(imgs.shape)
if super_res is not None:
shapes[2], shapes[3] = int(shapes[2] / super_res), int(shapes[3] / super_res)
_transform = transforms.Resize((shapes[2], shapes[3]))
imgs_transformed = _transform(imgs)
imgs_transformed = imgs_transformed.to(device)
imgs = imgs.to(device)
labels = labels.to(device)
if noisy is not None:
test_noisy_tensor = noisy[1]
else:
test_noisy_tensor = torch.zeros(tuple(shapes)).to(device)
if super_res is None:
imgs_noisy = imgs + test_noisy_tensor
else:
imgs_noisy = imgs_transformed + test_noisy_tensor
imgs_noisy = torch.clamp(imgs_noisy, 0., 1.)
preds = model(imgs_noisy)
loss = loss_fn(preds, imgs)
test_loss += loss.item()
train_loss /= len(train_dataloader)
test_loss /= len(test_dataloader)
tqdm_dct = {'train loss:': train_loss, 'test loss:': test_loss}
tqdm_iter.set_postfix(tqdm_dct, refresh=True)
tqdm_iter.refresh()
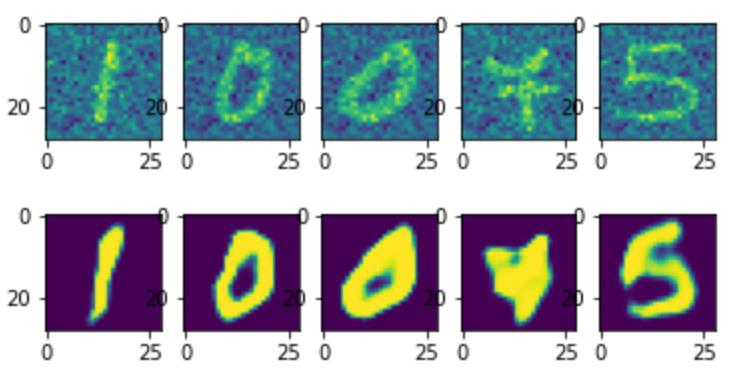
训练:
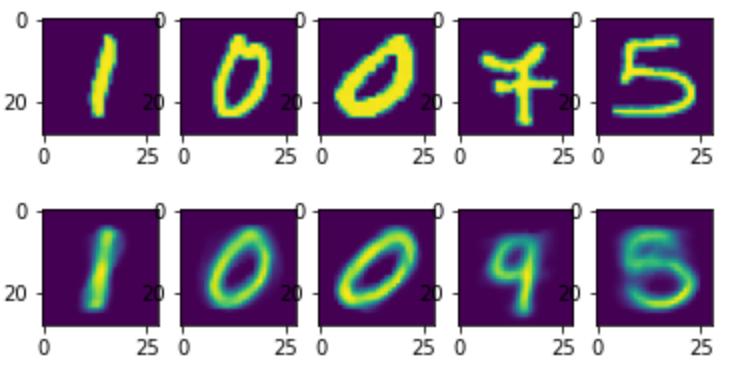
train(dataloaders, model, loss_fn, optimizer, epochs, device)
绘图:
model.eval()predictions = []plots = 5for i, data in enumerate(test_dataset):
if i == plots:
break
predictions.append(model(data[0].to(device).unsqueeze(0)).detach().cpu())
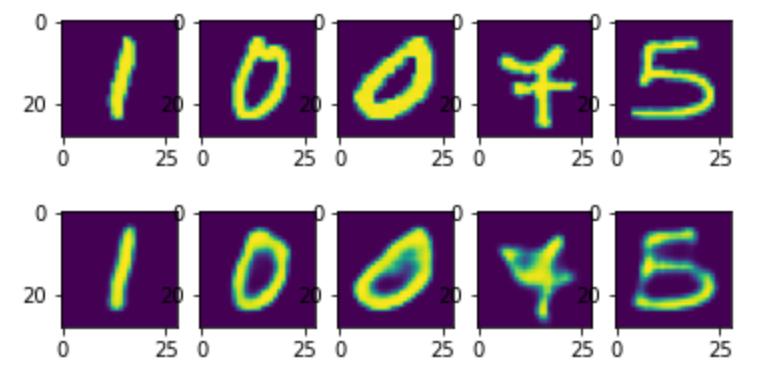
plotn(plots, test_dataset)
plotn(plots, predictions)
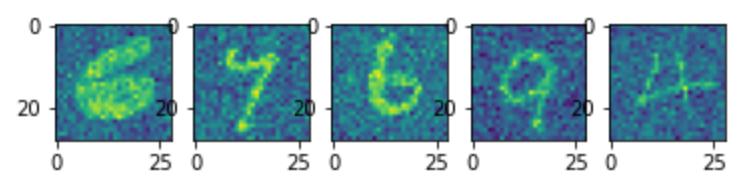
降噪:MINIST为例
绘图:
plotn(5, train_dataset, noisy=True)

model = AutoEncoder().to(device)
optimizer = optim.Adam(model.parameters(), lr=lr, eps=eps)
loss_fn = nn.BCELoss()
noisy_tensor = torch.FloatTensor(noisify([256, 1, 28, 28])).to(device)
test_noisy_tensor = torch.FloatTensor(noisify([1, 1, 28, 28])).to(device)
noisy_tensors = (noisy_tensor, test_noisy_tensor)
train(dataloaders, model, loss_fn, optimizer, 100, device, noisy=noisy_tensors)
model.eval()predictions = []noise = []plots = 5for i, data in enumerate(test_dataset):
if i == plots:
break
shapes = data[0].shape
noisy_data = data[0] + test_noisy_tensor[0].detach().cpu()
noise.append(noisy_data)
predictions.append(model(noisy_data.to(device).unsqueeze(0)).detach().cpu())
plotn(plots, noise)
plotn(plots, predictions)
绘图:
plotn(5, train_dataset, noisy=True)
model = AutoEncoder().to(device)
optimizer = optim.Adam(model.parameters(), lr=lr, eps=eps)
loss_fn = nn.BCELoss()
noisy_tensor = torch.FloatTensor(noisify([256, 1, 28, 28])).to(device)
test_noisy_tensor = torch.FloatTensor(noisify([1, 1, 28, 28])).to(device)
noisy_tensors = (noisy_tensor, test_noisy_tensor)
训练:
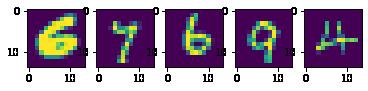
train(dataloaders, model, loss_fn, optimizer, 100, device, noisy=noisy_tensors)
model.eval()
predictions = []
noise = []
plots = 5
for i, data in enumerate(test_dataset):
if i == plots:
break
shapes = data[0].shape
noisy_data = data[0] + test_noisy_tensor[0].detach().cpu()
noise.append(noisy_data)
predictions.append(model(noisy_data.to(device).unsqueeze(0)).detach().cpu())
plotn(plots, noise)
plotn(plots, predictions)
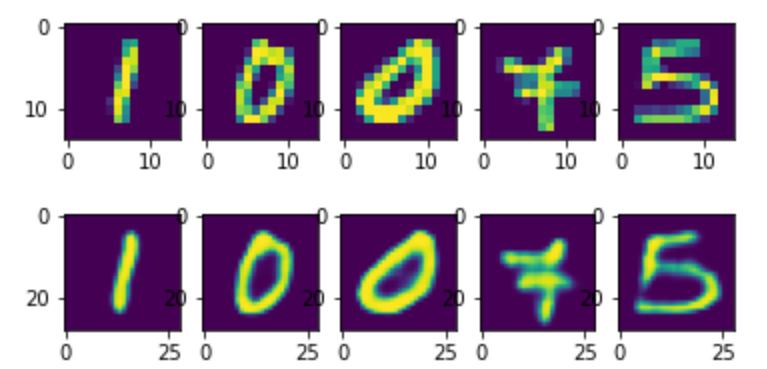
超分辨率:
三个步骤:
-
数据准备:输入(高分辨率图28x28 -> 下采样到14x14,用双线性插值/平均池化),输出(保持)
-
编码器(压缩低分辨率图14x14->7x7),解码器(上采样重建高分辨率图7x7->28x28,用转置卷积或插值+卷积)
-
训练目标:顺势函数MSE或感知损失
super_res_koeff = 2.0plotn(5, train_dataset, super_res=super_res_koeff)
class SuperResolutionEncoder(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, 16, kernel_size=(3, 3), padding='same')
self.maxpool1 = nn.MaxPool2d(kernel_size=(2, 2))
self.conv2 = nn.Conv2d(16, 8, kernel_size=(3, 3), padding='same')
self.maxpool2 = nn.MaxPool2d(kernel_size=(2, 2), padding=(1, 1))
self.relu = nn.ReLU()
def forward(self, input):
hidden1 = self.maxpool1(self.relu(self.conv1(input)))
encoded = self.maxpool2(self.relu(self.conv2(hidden1)))
return encoded
model = AutoEncoder(super_resolution=True).to(device)
optimizer = optim.Adam(model.parameters(), lr=lr, eps=eps)
loss_fn = nn.BCELoss()
train(dataloaders, model, loss_fn, optimizer, epochs, device, super_res=2.0)
model.eval()
predictions = []plots = 5
shapes = test_dataset[0][0].shape
for i, data in enumerate(test_dataset):
if i == plots:
break
_transform = transforms.Resize((int(shapes[1] / super_res_koeff), int(shapes[2] / super_res_koeff)))
predictions.append(model(_transform(data[0]).to(device).unsqueeze(0)).detach().cpu())
plotn(plots, test_dataset, super_res=super_res_koeff)
plotn(plots, predictions)
传统自编码器:潜在向量缺语义解释性
潜在向量空间上的邻近点可对应不同数字(A靠近B,但是A=0,B=1);不能就直接用潜在向量判断对应类别,要解码成图像后才能识别
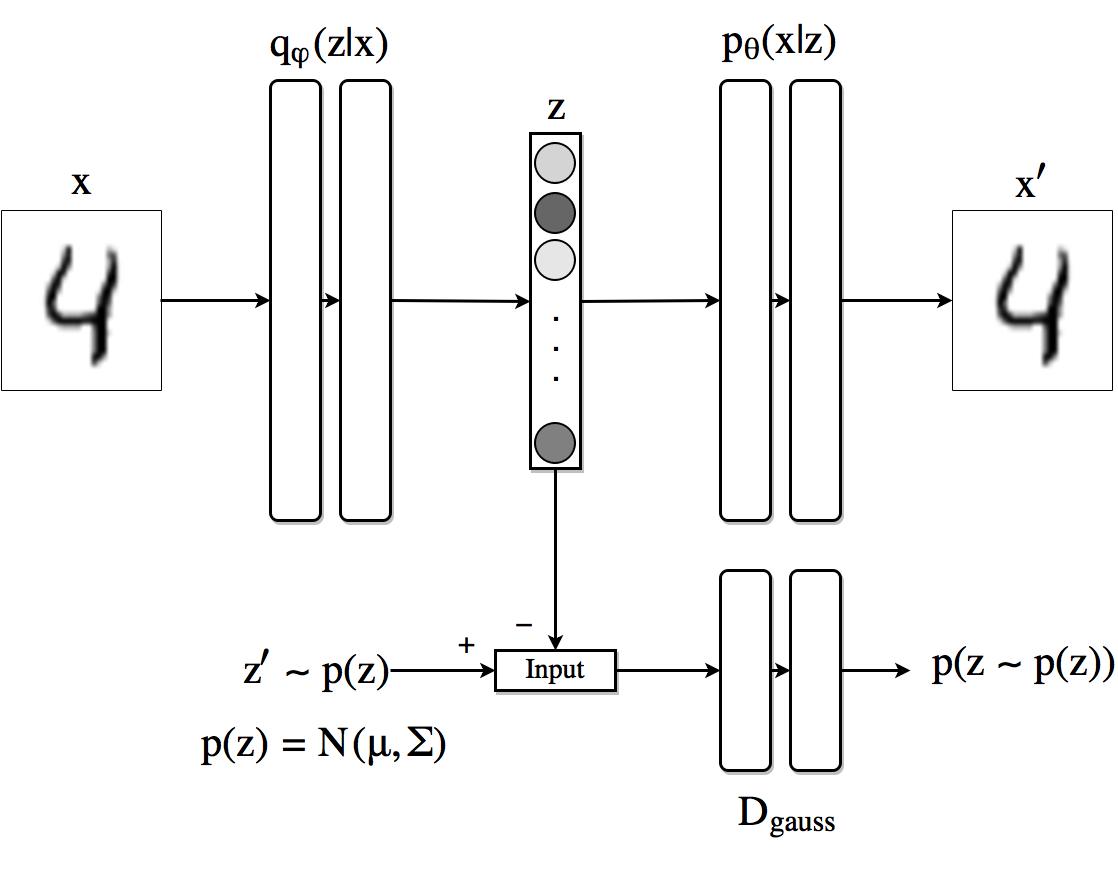
变分自编码器VAE:理解数据的潜在空间分布来生成新样本(让编码器学习数据潜在分布)
步骤:
-
预测分布参数:输入图像,用编码器预测参数(均值z_mean和对数方差z_log);直接预测对数方差保证数值稳定性
-
采样潜在向量:高斯分布N(z_mean,e^z_log)随机采样一个向量(sample=z_mean+ε*exp(z_log/2)),ε服从标准正态
-
重建图像:解码器将采样的潜在向量转换成重建图->还原原始输入
class VAEEncoder(nn.Module):
def __init__(self, device):
super().__init__()
self.intermediate_dim = 512
self.latent_dim = 2
self.linear = nn.Linear(784, self.intermediate_dim)
self.z_mean = nn.Linear(self.intermediate_dim, self.latent_dim)
self.z_log = nn.Linear(self.intermediate_dim, self.latent_dim)
self.relu = nn.ReLU()
self.device = device
def forward(self, input):
bs = input.shape[0]
hidden = self.relu(self.linear(input))
z_mean = self.z_mean(hidden)
z_log = self.z_log(hidden)
eps = torch.FloatTensor(np.random.normal(size=(bs, self.latent_dim))).to(device)
z_val = z_mean + torch.exp(z_log) * eps
return z_mean, z_log, z_val
class VAEDecoder(nn.Module):
def __init__(self):
super().__init__()
self.intermediate_dim = 512
self.latent_dim = 2
self.linear = nn.Linear(self.latent_dim, self.intermediate_dim)
self.output = nn.Linear(self.intermediate_dim, 784)
self.relu = nn.ReLU()
self.sigmoid = nn.Sigmoid()
def forward(self, input):
hidden = self.relu(self.linear(input))
decoded = self.sigmoid(self.output(hidden))
return decoded
class VAEAutoEncoder(nn.Module):
def __init__(self, device):
super().__init__()
self.encoder = VAEEncoder(device)
self.decoder = VAEDecoder()
self.z_vals = None
def forward(self, input):
bs, c, h, w = input.shape[0], input.shape[1], input.shape[2], input.shape[3]
input = input.view(bs, -1)
encoded = self.encoder(input)
self.z_vals = encoded
decoded = self.decoder(encoded[2])
return decoded
def get_zvals(self):
return self.z_vals
VAE的损失函数:
重建损失:衡量重建图和原图的差异(MSE)
KL损失:强制潜在分布标准接近标准正态分布N(0,1),用KL散度量化分布差异
def vae_loss(preds, targets, z_vals):
mse = nn.MSELoss()
reconstruction_loss = mse(preds, targets.view(targets.shape[0], -1)) * 784.0
temp = 1.0 + z_vals[1] - torch.square(z_vals[0]) - torch.exp(z_vals[1])
kl_loss = -0.5 * torch.sum(temp, axis=-1)
return torch.mean(reconstruction_loss + kl_loss)
model = VAEAutoEncoder(device).to(device)
optimizer = optim.RMSprop(model.parameters(), lr=lr, eps=eps)
def train_vae(dataloaders, model, optimizer, epochs, device):
tqdm_iter = tqdm(range(epochs))
train_dataloader, test_dataloader = dataloaders[0], dataloaders[1]
for epoch in tqdm_iter:
model.train()
train_loss = 0.0
test_loss = 0.0
for batch in train_dataloader:
imgs, labels = batch
imgs = imgs.to(device)
labels = labels.to(device)
preds = model(imgs)
z_vals = model.get_zvals()
loss = vae_loss(preds, imgs, z_vals)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss += loss.item()
model.eval()
with torch.no_grad():
for batch in test_dataloader:
imgs, labels = batch
imgs = imgs.to(device)
labels = labels.to(device)
preds = model(imgs)
z_vals = model.get_zvals()
loss = vae_loss(preds, imgs, z_vals)
test_loss += loss.item()
train_loss /= len(train_dataloader)
test_loss /= len(test_dataloader)
tqdm_dct = {'train loss:': train_loss, 'test loss:': test_loss}
tqdm_iter.set_postfix(tqdm_dct, refresh=True)
tqdm_iter.refresh()
train_vae(dataloaders, model, optimizer, epochs, device)
model.eval()predictions = []
plots = 5
for i, data in enumerate(test_dataset):
if i == plots:
break
predictions.append(model(data[0].to(device).unsqueeze(0)).view(1, 28, 28).detach().cpu())
plotn(plots, test_dataset)
plotn(plots, predictions)
对抗自编码器:AAE
编码器/生成器:输入映射到潜在空间
解码器:潜在空间重建图像
判别器:区分编码器输出分布和目标分布
AAE的损失函数:
重建损失:VAE
对抗损失:GAN
class AAEEncoder(nn.Module):
def __init__(self, input_dim, inter_dim, latent_dim):
super().__init__()
self.linear1 = nn.Linear(input_dim, inter_dim)
self.linear2 = nn.Linear(inter_dim, inter_dim)
self.linear3 = nn.Linear(inter_dim, inter_dim)
self.linear4 = nn.Linear(inter_dim, latent_dim)
self.relu = nn.ReLU()
def forward(self, input):
hidden1 = self.relu(self.linear1(input))
hidden2 = self.relu(self.linear2(hidden1))
hidden3 = self.relu(self.linear3(hidden2))
encoded = self.linear4(hidden3)
return encoded
class AAEDecoder(nn.Module):
def __init__(self, latent_dim, inter_dim, output_dim):
super().__init__()
self.linear1 = nn.Linear(latent_dim, inter_dim)
self.linear2 = nn.Linear(inter_dim, inter_dim)
self.linear3 = nn.Linear(inter_dim, inter_dim)
self.linear4 = nn.Linear(inter_dim, output_dim)
self.relu = nn.ReLU()
self.sigmoid = nn.Sigmoid()
def forward(self, input):
hidden1 = self.relu(self.linear1(input))
hidden2 = self.relu(self.linear2(hidden1))
hidden3 = self.relu(self.linear3(hidden2))
decoded = self.sigmoid(self.linear4(hidden3))
return decoded
class AAEDiscriminator(nn.Module):
def __init__(self, latent_dim, inter_dim):
super().__init__()
self.latent_dim = latent_dim
self.inter_dim = inter_dim
self.linear1 = nn.Linear(latent_dim, inter_dim)
self.linear2 = nn.Linear(inter_dim, inter_dim)
self.linear3 = nn.Linear(inter_dim, inter_dim)
self.linear4 = nn.Linear(inter_dim, inter_dim)
self.linear5 = nn.Linear(inter_dim, 1)
self.relu = nn.ReLU()
self.sigmoid = nn.Sigmoid()
def forward(self, input):
hidden1 = self.relu(self.linear1(input))
hidden2 = self.relu(self.linear2(hidden1))
hidden3 = self.relu(self.linear3(hidden2))
hidden4 = self.relu(self.linear4(hidden3))
decoded = self.sigmoid(self.linear4(hidden4))
return decoded
def get_dims(self):
return self.latent_dim, self.inter_dim
input_dims = 784
inter_dims = 1000
latent_dims = 150
aae_encoder = AAEEncoder(input_dims, inter_dims, latent_dims).to(device)
aae_decoder = AAEDecoder(latent_dims, inter_dims, input_dims).to(device)
aae_discriminator = AAEDiscriminator(latent_dims, int(inter_dims / 2)).to(device)
lr = 1e-4
regularization_lr = 5e-5
optim_encoder = optim.Adam(aae_encoder.parameters(), lr=lr)
optim_encoder_regularization = optim.Adam(aae_encoder.parameters(), lr=regularization_lr)
optim_decoder = optim.Adam(aae_decoder.parameters(), lr=lr)
optim_discriminator = optim.Adam(aae_discriminator.parameters(), lr=regularization_lr)
def train_aae(dataloaders, models, optimizers, epochs, device):
tqdm_iter = tqdm(range(epochs))
train_dataloader, test_dataloader = dataloaders[0], dataloaders[1]
enc, dec, disc = models[0], models[1], models[2]
optim_enc, optim_enc_reg, optim_dec, optim_disc = optimizers[0], optimizers[1], optimizers[2], optimizers[3]
eps = 1e-9
for epoch in tqdm_iter:
enc.train()
dec.train()
disc.train()
train_reconst_loss = 0.0
train_disc_loss = 0.0
train_enc_loss = 0.0
test_reconst_loss = 0.0
test_disc_loss = 0.0
test_enc_loss = 0.0
for batch in train_dataloader:
imgs, labels = batch
imgs = imgs.view(imgs.shape[0], -1).to(device)
labels = labels.to(device)
enc.zero_grad()
dec.zero_grad()
disc.zero_grad()
encoded = enc(imgs)
decoded = dec(encoded)
reconstruction_loss = F.binary_cross_entropy(decoded, imgs)
reconstruction_loss.backward()
optim_enc.step()
optim_dec.step()
enc.eval()
latent_dim, disc_inter_dim = disc.get_dims()
real = torch.randn(imgs.shape[0], latent_dim).to(device)
disc_real = disc(real)
disc_fake = disc(enc(imgs))
disc_loss = -torch.mean(torch.log(disc_real + eps) + torch.log(1.0 - disc_fake + eps))
disc_loss.backward()
optim_dec.step()
enc.train()
disc_fake = disc(enc(imgs))
enc_loss = -torch.mean(torch.log(disc_fake + eps))
enc_loss.backward()
optim_enc_reg.step()
train_reconst_loss += reconstruction_loss.item()
train_disc_loss += disc_loss.item()
train_enc_loss += enc_loss.item()
enc.eval()
dec.eval()
disc.eval()
with torch.no_grad():
for batch in test_dataloader:
imgs, labels = batch
imgs = imgs.view(imgs.shape[0], -1).to(device)
labels = labels.to(device)
encoded = enc(imgs)
decoded = dec(encoded)
reconstruction_loss = F.binary_cross_entropy(decoded, imgs)
latent_dim, disc_inter_dim = disc.get_dims()
real = torch.randn(imgs.shape[0], latent_dim).to(device)
disc_real = disc(real)
disc_fake = disc(enc(imgs))
disc_loss = -torch.mean(torch.log(disc_real + eps) + torch.log(1.0 - disc_fake + eps))
disc_fake = disc(enc(imgs))
enc_loss = -torch.mean(torch.log(disc_fake + eps))
test_reconst_loss += reconstruction_loss.item()
test_disc_loss += disc_loss.item()
test_enc_loss += enc_loss.item()
train_reconst_loss /= len(train_dataloader)
train_disc_loss /= len(train_dataloader)
train_enc_loss /= len(train_dataloader)
test_reconst_loss /= len(test_dataloader)
test_disc_loss /= len(test_dataloader)
test_enc_loss /= len(test_dataloader)
tqdm_dct = {'train reconst loss:': train_reconst_loss, 'train disc loss:': train_disc_loss, 'train enc loss': train_enc_loss, \
'test reconst loss:': test_reconst_loss, 'test disc loss:': test_disc_loss, 'test enc loss': test_enc_loss}
tqdm_iter.set_postfix(tqdm_dct, refresh=True)
tqdm_iter.refresh()
models = (aae_encoder, aae_decoder, aae_discriminator)
optimizers = (optim_encoder, optim_encoder_regularization, optim_decoder, optim_discriminator)
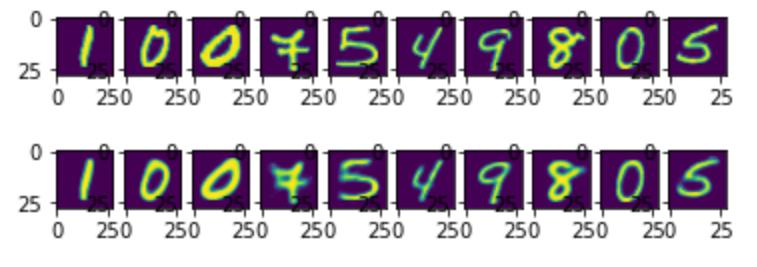
train_aae(dataloaders, models, optimizers, epochs, device)
aae_encoder.eval()aae_decoder.eval()predictions = []plots = 10
for i, data in enumerate(test_dataset):
if i == plots:
break
pred = aae_decoder(aae_encoder(data[0].to(device).unsqueeze(0).view(1, 784)))
predictions.append(pred.view(1, 28, 28).detach().cpu())
plotn(plots, test_dataset)
plotn(plots, predictions)
扩展阅读:
-
训练二维潜在的向量自编码器
-
潜在空间扰动实验
-
Fashion MNIST+降噪器实验
-
用CIFAR-10数据集训练超分辨率网络(2倍4倍放大,观察4倍放大模型输入噪声)
-
基于传统自编码器CNN构建CNN版本VAE
-
TensorFlow框架下的自编码器实践(还没写,因为TensorFlow现在少人)