项目地址:https://chat.qwen.ai/
这是 Qwen 系列中全新的旗舰级多模态大模型,专为全面的多模式感知设计,可以无缝处理包括文本、图像、音频和视频的各种输入,同时支持流式的文本生成和自然语音合成输出。

这张图片展示了Qwen2.5-Omni多模态系统的工作流程,该系统能够处理视觉、文本和音频信息。图片分为六个部分,每个部分展示了不同的功能和应用场景。以下是详细分析:
-
Video-Chat(视频聊天):
- Query(查询):询问左边和右边的人分别说了什么。
- Response(响应):左边的人说“欢迎所有人来到节目”,右边的人说了一段感谢的话。
-
Text-Chat(文本聊天):
- Query:询问能否帮助写一条给妈妈的母亲节祝福信息。
- Response:生成了一段感谢妈妈的话,表达了对妈妈的爱和感激之情。
-
Image-Chat(图像聊天):
- Query:请求帮助解决一个数学问题(X + Y = 10,X = 2,求Y)。
- Response:通过计算得出Y的值是8。
-
Audio-Chat(音频聊天):
- Query:请求对一首音乐的简短描述。
- Response:描述了一首A大调流行音乐,4/4拍,主要和弦交替为A大调和D大调,节奏约为每分钟90拍。
-
系统架构:
- 中间部分展示了Qwen2.5-Omni系统的核心组件,包括视觉编码器、音频编码器、文本思考器和文本说话器。这些组件协同工作,实现多模态的交互。
从此以后,你可以像打电话或进行视频通话一样与 Qwen 聊天!可以说是「语音聊天 + 视频聊天」都实现了。
论文地址:https://github.com/QwenLM/Qwen2.5-Omni/blob/main/assets/Qwen2.5_Omni.pdf
博客地址:https://qwenlm.github.io/blog/qwen2.5-omni/
GitHub 地址:https://github.com/QwenLM/Qwen2.5-Omni
Hugging Face 地址:https://huggingface.co/Qwen/Qwen2.5-Omni-7B
ModelScope:https://modelscope.cn/models/Qwen/Qwen2.5-Omni-7B
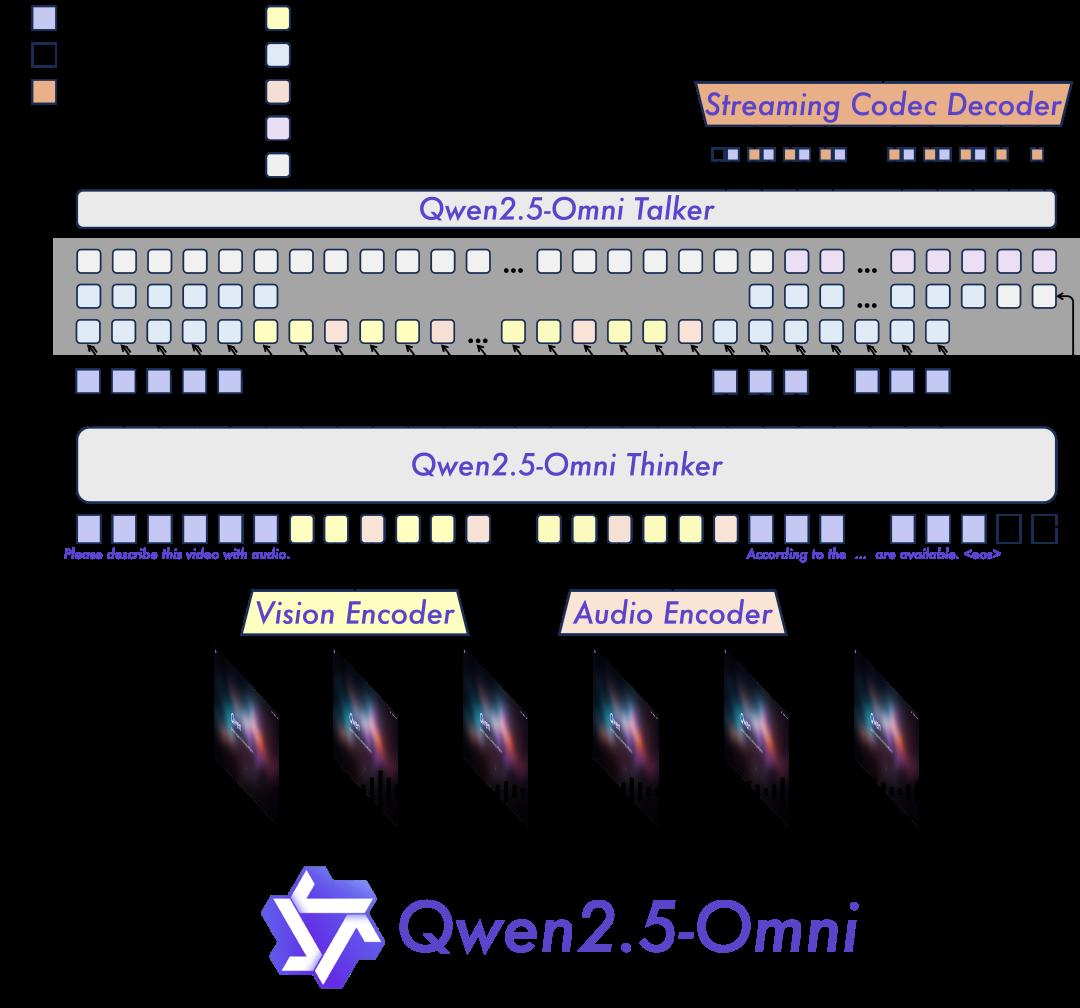
Qwen2.5-Omni模型架构的特点:
首先是Omni 和创新架构,团队提出了 Thinker-Talker 架构,这是一个端到端的多模态模型,旨在感知包括文本、图像、音频和视频在内的多种模态,同时以流式方式生成文本和自然语音响应。此外,团队还提出了一种名为 TMRoPE(Time-aligned Multimodal RoPE)的新型位置嵌入,用于同步视频输入与音频的时间戳;
实时语音和视频聊天:该架构专为完全实时交互而设计,支持分块输入和即时输出。
自然且稳健的语音生成:在语音生成方面,Qwen2.5-Omni 超越了许多现有的流式和非流式替代方案,展现出卓越的稳健性和自然性;
多模态性能强劲:在与同样大小的单模态模型进行基准测试时,Qwen2.5-Omni 在所有模态上均展现出卓越的性能。Qwen2.5-Omni 在音频能力上超越了同样大小的 Qwen2-Audio,并且达到了与 Qwen2.5-VL-7B 相当的性能;
出色的端到端语音指令遵循能力:Qwen2.5-Omni 在端到端语音指令遵循方面的表现可与文本输入的有效性相媲美,这一点在 MMLU 和 GSM8K 等基准测试中得到了证明。
Owen2.5-Omni采用的架构是Thinker-Talker架构。
对于图片中的术语解释:
-
Text Token(文本标记)、Vision Hidden(视觉隐藏状态)、Pad Token(填充标记)、Audio Hidden(音频隐藏状态)、Codec Token(编解码器标记):这些不同类型的标记和隐藏状态代表了系统中不同模态的信息。
-
Forward Propagation(前向传播)和Backward Propagation(后向传播):这两个过程描述了神经网络中信息的传播方向。前向传播是指信息从输入层经过各隐藏层传递到输出层的过程,而后向传播则是指通过梯度下降等方法调整网络参数的过程。
-
Qwen2.5-Omni Talker(说话者):这是系统的输出部分,负责生成对话的文本内容。
-
Qwen2.5-Omni Thinker(思考者):这是系统的处理核心,负责处理输入的多模态信息,并生成相应的隐藏状态。
-
Vision Encoder(视觉编码器)和Audio Encoder(音频编码器):这两个编码器分别负责将视觉和音频信息编码为模型可以处理的格式。
-
Streaming Codec Decoder(流式编解码器解码器):这个组件负责解码经过编码的文本信息,以便系统能够理解并生成对话内容。
-
Sample(样本):图中展示了一些样本数据,这些数据用于训练和测试系统。
-
请根据视频描述音频:这是一个提示,表明系统需要利用视觉和音频信息来生成相应的文本描述。
-
Qwen2.5-Omni:这是整个系统的名称,强调了其多模态处理的能力。
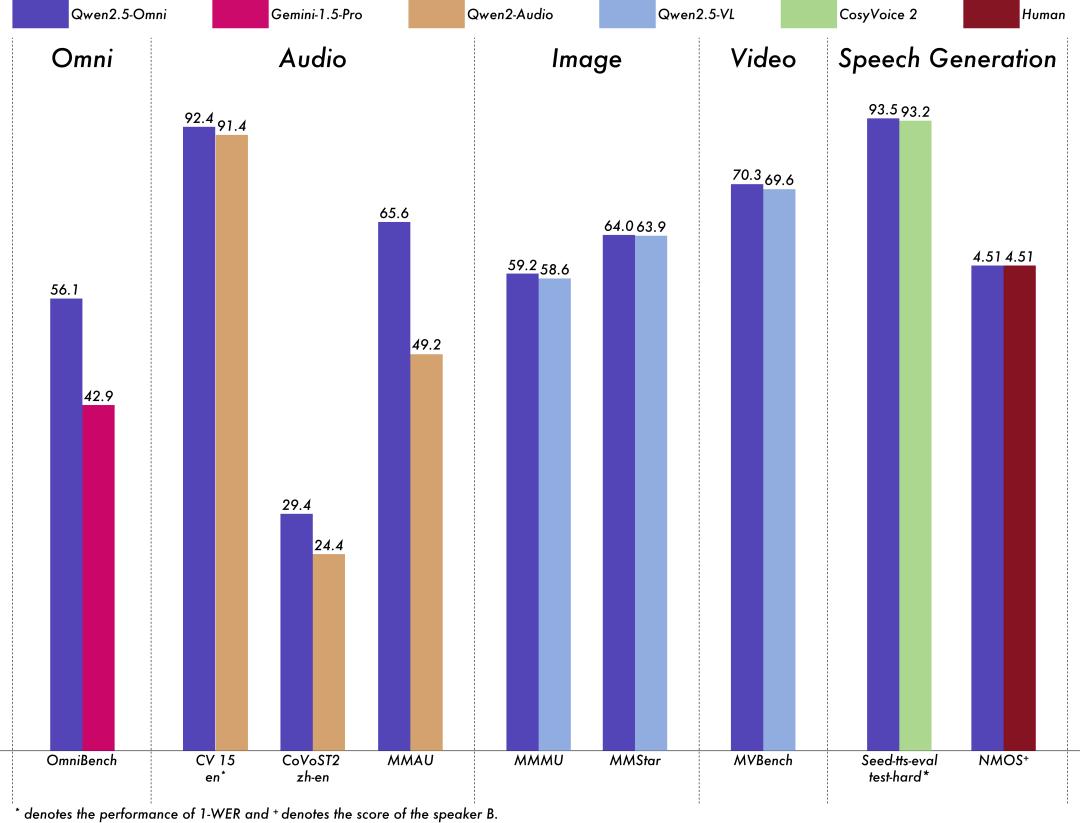
模型性能:
团队人员对 Qwen2.5-Omni 进行了全面评估,结果表明,该模型在所有模态上的表现均优于类似大小的单模态模型以及闭源模型,例如 Qwen2.5-VL-7B、Qwen2-Audio 和 Gemini-1.5-pro。在需要集成多种模态的任务中,如 OmniBench,Qwen2.5-Omni 达到了最先进的水平。此外,在单模态任务中,Qwen2.5-Omni 在多个领域中表现优异,包括语音识别(Common Voice)、翻译(CoVoST2)、音频理解(MMAU)、图像推理(MMMU, MMStar)、视频理解(MVBench)以及语音生成(Seed-tts-eval 和 subjective naturalness)。
亲测:感觉不错,但是跟DeepSeek官网的R1比起来还是差了点。