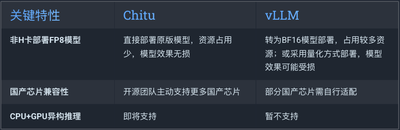
清华系科创企业清程极智与清华大学翟季冬教授团队联合宣布开源大模型推理引擎「赤兔」(Chitu),率先实现了非 H 卡设备(英伟达 Hopper 架构之前的 GPU 卡及各类国产卡)运行原生 FP8 模型的突破。在 A800 集群上的实测数据显示,用赤兔引擎部署 DeepSeek-671B 满血版推理服务,相比于 vLLM 部署方案,不仅使用的 GPU 数量减少了 50%,而且输出速度还提升了 3.15 倍。
开源代码库:https://github.com/thu-pacman/chitu
模型:赤兔Chitu
当前,拥有完整自主可控的 AI 技术栈已成为国家战略性需求。DeepSeek、QwQ 等优秀的国产开源大模型正在重塑全球科技产业格局,但在大模型推理部署领域,业界仍高度依赖国外开源工具。赤兔引擎的开源为业界提供了国产开源新选择,也意味着「国产大模型 + 国产引擎 + 国产芯片」的完整技术闭环正在加速形成。「我们看到国内大模型领域取得了显著进步,但在基础设施层面,尤其是推理引擎这一核心环节仍缺乏生产级开源产品。」清程极智 CEO 汤雄超表示,「开源赤兔引擎是我们助力国内 AI 生态建设的重要一步。」
作为清华大学高性能计算研究所所长,翟季冬教授长期致力于高性能计算与系统软件优化研究。翟教授指出:「赤兔引擎凝结了团队多年的并行计算与编译优化技术积累,目标是建立一个真正适合国内多元算力环境的高性能推理引擎,能够弥合先进模型与多样化硬件之间的差距,为中国大模型的产业落地提供关键支撑。」
核心优势:全场景性能优化和架构适应性,本次开源的版本特别聚焦于当前市场最迫切的需求 —— 即实现 DeepSeek FP8 精度模型在存量英伟达 GPU 上的无损且高效部署。团队还透露,针对多款国产芯片特别优化的版本也将相继对外开源。这一突破不仅降低了大模型落地门槛,也为国产 AI 算力的发展带来了新的契机。「最先进的模型与最难获取的硬件绑定,这是当前企业大模型落地的最大痛点之一」汤雄超表示。随着更新一代模型和芯片往 FP4 等新型数据精度方向的发展,这种代际效应将愈发显著。
另一个挑战是现有开源推理引擎对多元算力环境的支持不足。当前,vLLM 等主流引擎主要针对 NVIDIA 最新架构优化,对国产芯片或较老款 GPU 的适配并不理想。在国内企业私有化部署场景中,NVIDIA 的 Ampere 系列 GPU、国产芯片等多元算力占据了相当比例,这些场景亟需更加灵活的解决方案。
-
多元算力适配:不仅支持 NVIDIA 最新旗舰到旧款的多种型号,也为国产芯片提供优化支持。 -
全场景可伸缩:从纯 CPU 部署、单 GPU 部署到大规模集群部署,赤兔引擎提供可扩展的解决方案。 -
长期稳定运行:可应用于实际生产环境,稳定性足以承载并发业务流量。

本次开源的技术突破是实现非 H 卡设备原生运行 DeepSeek FP8 精度模型。「我们没有走简单的量化路线,而是通过在算子内部高效处理 FP8 数据,确保模型推理质量不受任何影响。」汤雄超表示:「具体来说,我们对 GeMM、MoE 等一系列关键算子进行了指令级的优化,实现了 FP8 数据的原生处理能力。」
代码库分析:待定