
阿里开源发布了新推理模型 QwQ-32B,其参数量为 320 亿,但性能足以比肩 6710 亿参数的 DeepSeek-R1 满血版。千问的推文表示:「这次,我们研究了扩展 RL 的方法,并基于我们的 Qwen2.5-32B 取得了一些令人印象深刻的成果。我们发现 RL 训练可以不断提高性能,尤其是在数学和编码任务上,并且我们观察到 RL 的持续扩展可以帮助中型模型实现与巨型 MoE 模型相媲美的性能。欢迎与我们的新模型聊天并向我们提供反馈!」QwQ-32B 已在 Hugging Face 和 ModelScope 开源,采用了 Apache 2.0 开源协议。大家也可通过 Qwen Chat 直接进行体验!
博客:https://qwenlm.github.io/zh/blog/qwq-32b/
Hugging Face:https://huggingface.co/Qwen/QwQ-32B
演示:https://huggingface.co/spaces/Qwen/QwQ-32B-Demo
Qwen Chat:https://chat.qwen.ai/
本地部署工具 Ollama 也第一时间提供了支持:ollama run qwq。
千问官方发布了题为「QwQ-32B: 领略强化学习之力」的官方中文博客介绍这一吸睛无数的进展。考虑到强化学习之父 Richard Sutton 与导师 Andrew Barto 刚刚获得图灵奖,QwQ-32B 的发布可说是非常应景。
博客中写到,大规模强化学习(RL)非常具有潜力,在提升模型性能方面可望超越传统的预训练和后训练方法。近期的研究表明,强化学习可以显著提高模型的推理能力。例如,DeepSeek-R1 通过整合冷启动数据和多阶段训练,实现了最先进的性能,使其能够进行深度思考和复杂推理。而千问团队则探索了大规模强化学习(RL)对大语言模型的智能的提升作用,推理模型 QwQ-32B 便由此而生。
这是一款拥有 320 亿参数的模型,其性能可媲美具备 6710 亿参数(其中 370 亿被激活)的 DeepSeek-R1。该团队表示:「这一成果突显了将强化学习应用于经过大规模预训练的强大基础模型的有效性。」
QwQ-32B 中还集成了与 Agent(智能体)相关的能力,使其能够在使用工具的同时进行批判性思考,并根据环境反馈调整推理过程。该团队表示:「我们希望我们的一点努力能够证明强大的基础模型叠加大规模强化学习也许是一条通往通用人工智能的可行之路。」
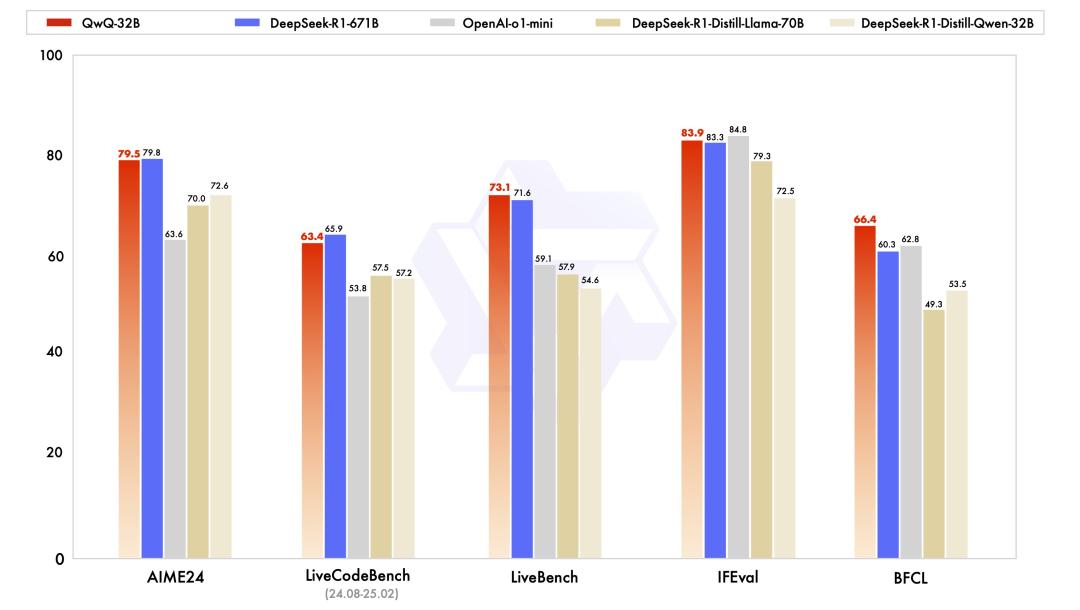
模型效果:
QwQ-32B 在一系列基准测试中进行了评估,包括数学推理、编程和通用能力。以下结果展示了 QwQ-32B 与其他领先模型的性能对比,包括 DeepSeek-R1-Distilled-Qwen-32B、DeepSeek-R1-Distilled-Llama-70B、o1-mini 以及原始的 DeepSeek-R1。
QwQ-32B强化学习:
QwQ-32B 的大规模强化学习是在冷启动的基础上开展的。
在初始阶段,先特别针对数学和编程任务进行 RL 训练。与依赖传统的奖励模型(reward model)不同,千问团队通过校验生成答案的正确性来为数学问题提供反馈,并通过代码执行服务器评估生成的代码是否成功通过测试用例来提供代码的反馈。随着训练轮次的推进,QwQ-32B 在这两个领域中的性能持续提升。在第一阶段的 RL 过后,他们又增加了另一个针对通用能力的 RL。此阶段使用通用奖励模型和一些基于规则的验证器进行训练。结果发现,通过少量步骤的通用 RL,可以提升其他通用能力,同时在数学和编程任务上的性能没有显著下降。
API调用模型:

个人评价:macbook pro M3 32G内存可以本地部署,体验流畅,和11月份发布过的那个QwQ版本不大不小,跟deepseek-r1-distill-32B比起来QwQ体验感好一些。