DeepSeek团队开源了一个名为 3FS(Fire-Flyer File System)的系统。这是一种并行文件系统,它利用现代固态硬盘(SSD)和远程直接内存访问(RDMA)网络的全部带宽,能够加速和推动 DeepSeek 平台上所有数据访问操作。
-
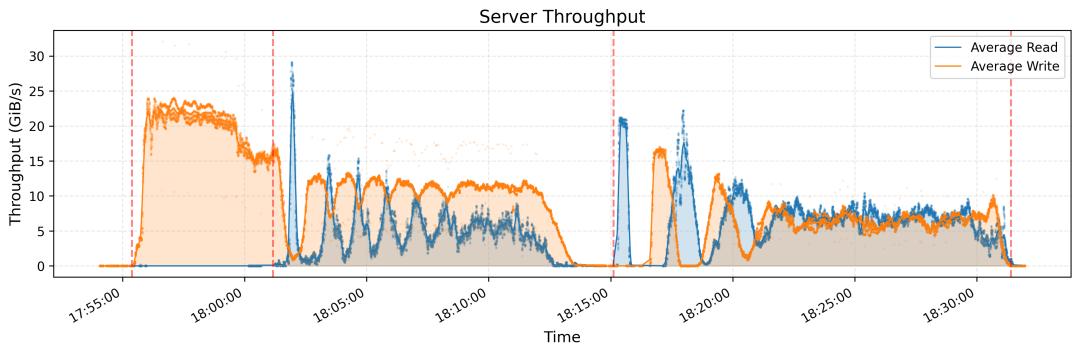
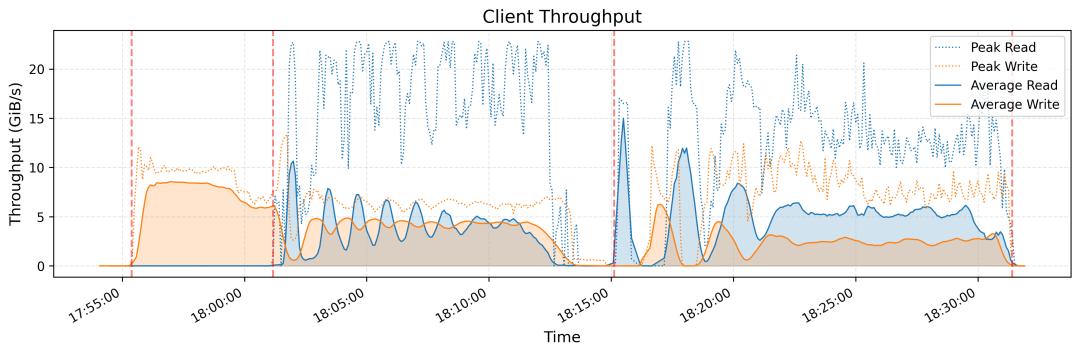
在 180 节点集群中实现了 6.6 TiB/s 的聚合读取吞吐量; -
在 25 节点集群的 GraySort 基准测试中达到 3.66 TiB/min 的吞吐量; -
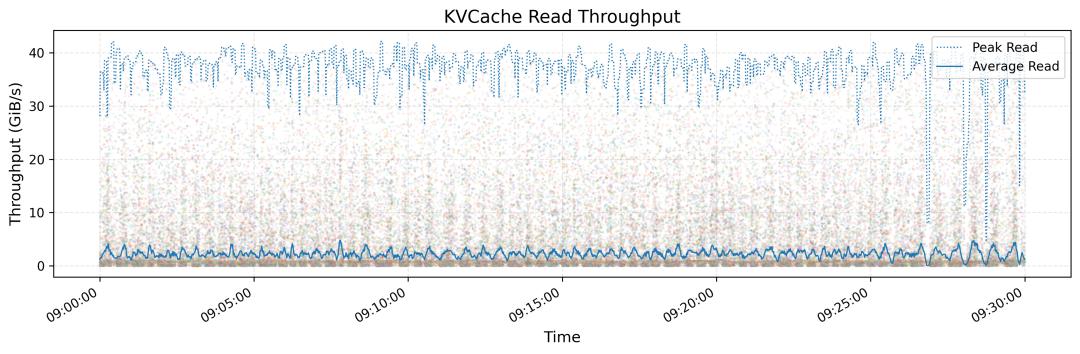
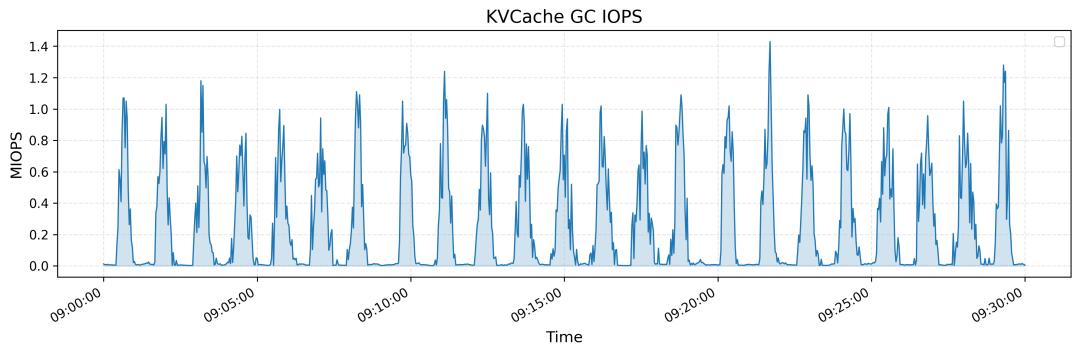
每个客户端节点在 KVCache 查找时可达到 40+ GiB/s 的峰值吞吐量; -
采用分离式架构,具有强一致性语义。
开源链接:https://github.com/deepseek-ai/3FS
Smallpond(3FS 上的数据处理框架):https://github.com/deepseek-ai/smallpond
3FS的应用场景:
-
分离式架构。结合了数千个 SSD 的吞吐量和数百个存储节点的网络带宽,使应用程序能够以不受位置限制的方式访问存储资源。
-
强一致性。实现了带有分配查询的链式复制(CRAQ)以保证强一致性,使应用程序代码简单且易于理解。
-
文件接口。开发了由事务性键值存储(如 FoundationDB)支持的无状态元数据服务。文件接口广为人知且随处可用。无需学习新的存储 API。
-
数据准备。将数据分析管道的输出组织成层次化的目录结构,并高效管理大量中间输出。
-
数据加载器。通过支持跨计算节点对训练样本的随机访问,消除了预取或打乱数据集的需求。
-
检查点保存。支持大规模训练的高吞吐量并行检查点保存。
-
用于推理的 KVCache。为基于 DRAM 的缓存提供了一种成本效益高的替代方案,提供高吞吐量和显著更大的容量。
3FS 性能:
灰度排序:DeepSeek 利用 GraySort 基准对 smallpond 进行了评估,该基准可衡量大规模数据集的排序性能。具体实现采用两阶段方法:(1) 使用键的前缀位通过 shuffle 对数据进行分区,以及 (2) 分区内排序。两个阶段都从 3FS 读取数据 / 向 3FS 写入数据。
测试集群由 25 个存储节点(2 个 NUMA 域 / 节点、1 个存储服务 / NUMA、2×400Gbps NIC / 节点)和 50 个计算节点(2 个 NUMA 域、192 个物理核心、2.2 TiB RAM 和 1×200 Gbps NIC / 节点)组成。对 8192 个分区中的 110.5 TiB 数据进行排序耗时 30 分 14 秒,平均吞吐量为 3.66 TiB / 分钟。