DeepSeek 的开源周已经进行到了第四天(前三天报道见文末「相关阅读」)。今天这家公司一口气发布了两个工具和一个数据集:DualPipe、EPLB 以及来自训练和推理框架的分析数据。DeepSeek 表示,DualPipe 曾在 V3/R1 的训练中使用,是一种用于计算 - 通信重叠的双向 pipeline 并行算法。EPLB 是为 V3/R1 打造的专家 - 并行负载均衡器。而公布训练和推理框架的分析数据是为了帮助社区更好地理解通信 - 计算重叠策略和底层实现细节。
DualPipe 链接:https://github.com/deepseek-ai/DualPipe
EPLB 链接:https://github.com/deepseek-ai/eplb
计算分析链接:https://github.com/deepseek-ai/profile-data
想象一下,训练一个庞大的语言模型就像指挥一个交响乐团。每个 GPU 就像一位音乐家,执行其分配的计算任务,而训练框架则充当指挥,保持一切完美同步。在典型设置中,音乐家们可能需要等待彼此,造成尴尬的停顿。这些延迟,被称为流水线气泡,会减慢整个过程。
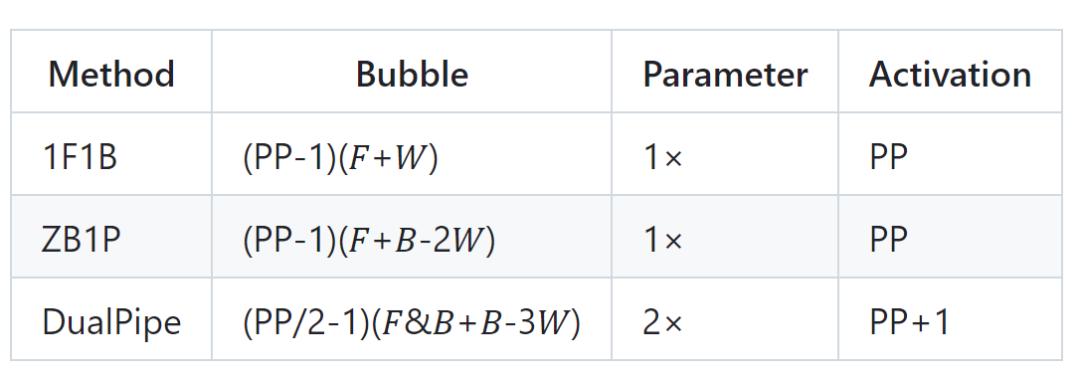
DualPipe 通过允许不同部分并行工作来消除这些低效,就像弦乐部演奏的同时铜管部也在排练。这种努力的重叠确保没有停机时间。
而关于 EPLB,我们可以这么理解:传统的数据并行就像给每个人一份整个项目的副本 —— 既浪费又缓慢。专家并行(EP),即每个专家驻留在不同的 GPU 上,如果可以平衡负载,则效率要高得多。EPLB 就是为了解决这种专家失衡问题而设计的。这不仅仅是分配专家;它是关于智能地分配它们,以最大限度地提高 GPU 利用率和最小化通信开销。
开源DualPipe:
调度:

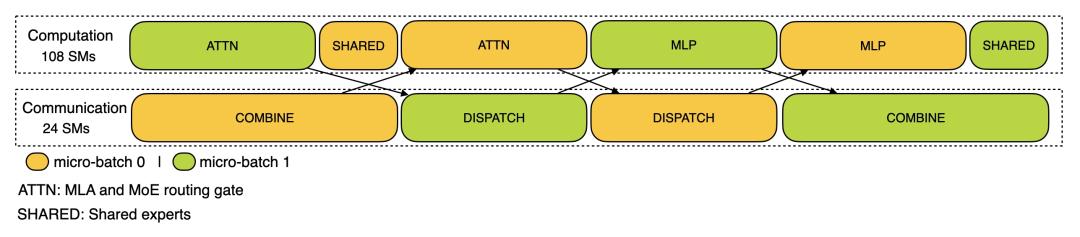
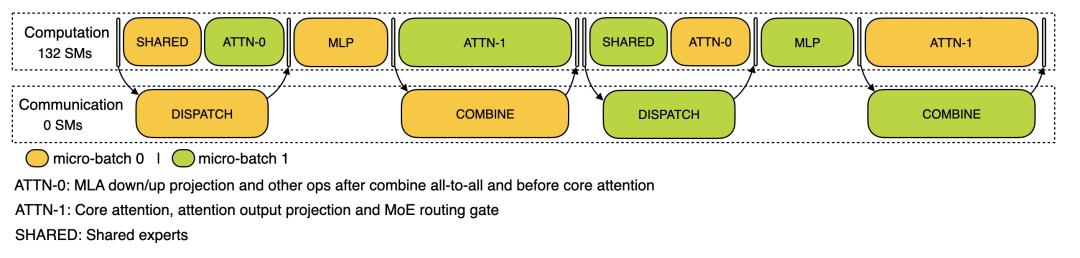
DualPipe 调度示例:8 个 流水线并行(PP)级别和 20 个双向 micro-batch。反向的 micro-batch 与前向的 micro-batch 对称,因此图中省略了它们的 batch ID 。被共享的黑色边框包围的两个单元格具有相互重叠的计算和通信。
开源EPLB:
在使用专家并行(Expert Parallelism,EP)时,不同的专家被分配到不同的 GPU 上。由于不同专家的负载可能会根据当前工作负载而变化,保持不同 GPU 之间的负载平衡非常重要。正如 DeepSeek-V3 论文中所描述的,工程师们采用了冗余专家策略,复制高负载的专家。然后,DeepSeek 通过启发式方法将这些复制的专家打包到 GPU 上,以确保不同 GPU 之间的负载平衡。
此外,得益于 DeepSeek-V3 中使用的组限制专家路由(group-limited expert routing),DeepSeek 工程师还尽可能地将同一组的专家放置在同一节点上,以减少节点间的数据传输。
为了便于复现和部署,DeepSeek 在 eplb.py 中开源了部署的 EP 负载平衡算法。该算法根据估计的专家负载计算出一个平衡的专家复制和放置方案。请注意,预测专家负载的确切方法超出了本仓库的范围。一种常见的方法是使用历史统计数据的移动平均值。