DeepSeek 的开源周已经进行到了第三天。今天开源的项目名叫 DeepGEMM,是一款支持密集型和专家混合(MoE)GEMM 的 FP8 GEMM 库,为 V3/R1 的训练和推理提供了支持,在 Hopper GPU 上可以达到 1350+ FP8 TFLOPS 的计算性能。
具体来说,DeepGEMM 是一个旨在实现简洁高效的 FP8 通用矩阵乘法(GEMM)的库,它采用了 DeepSeek-V3 中提出的细粒度 scaling 技术。该库支持普通 GEMM 以及专家混合(MoE)分组 GEMM。该库采用 CUDA 编写,在安装过程中无需编译,而是通过一个轻量级的 Just-In-Time(JIT)模块在运行时编译所有内核。
目前,DeepGEMM 仅支持英伟达 Hopper 张量核心。为了解决 FP8 张量核心累加不精确的问题,它采用了 CUDA 核心的两级累加(提升)机制。尽管它借鉴了 CUTLASS 和 CuTe 的一些概念,但避免了对其模板或代数的重度依赖。相反,该库的设计注重简洁性,仅包含一个核心内核函数,代码量仅为 300 行。这使其成为学习 Hopper FP8 矩阵乘法和优化技术的一个简洁且易于获取的资源。尽管设计轻量,DeepGEMM 在各种矩阵形状上的性能与专家调优的库相当,甚至在某些情况下更优。
开源地址:https://github.com/deepseek-ai/DeepGEMM
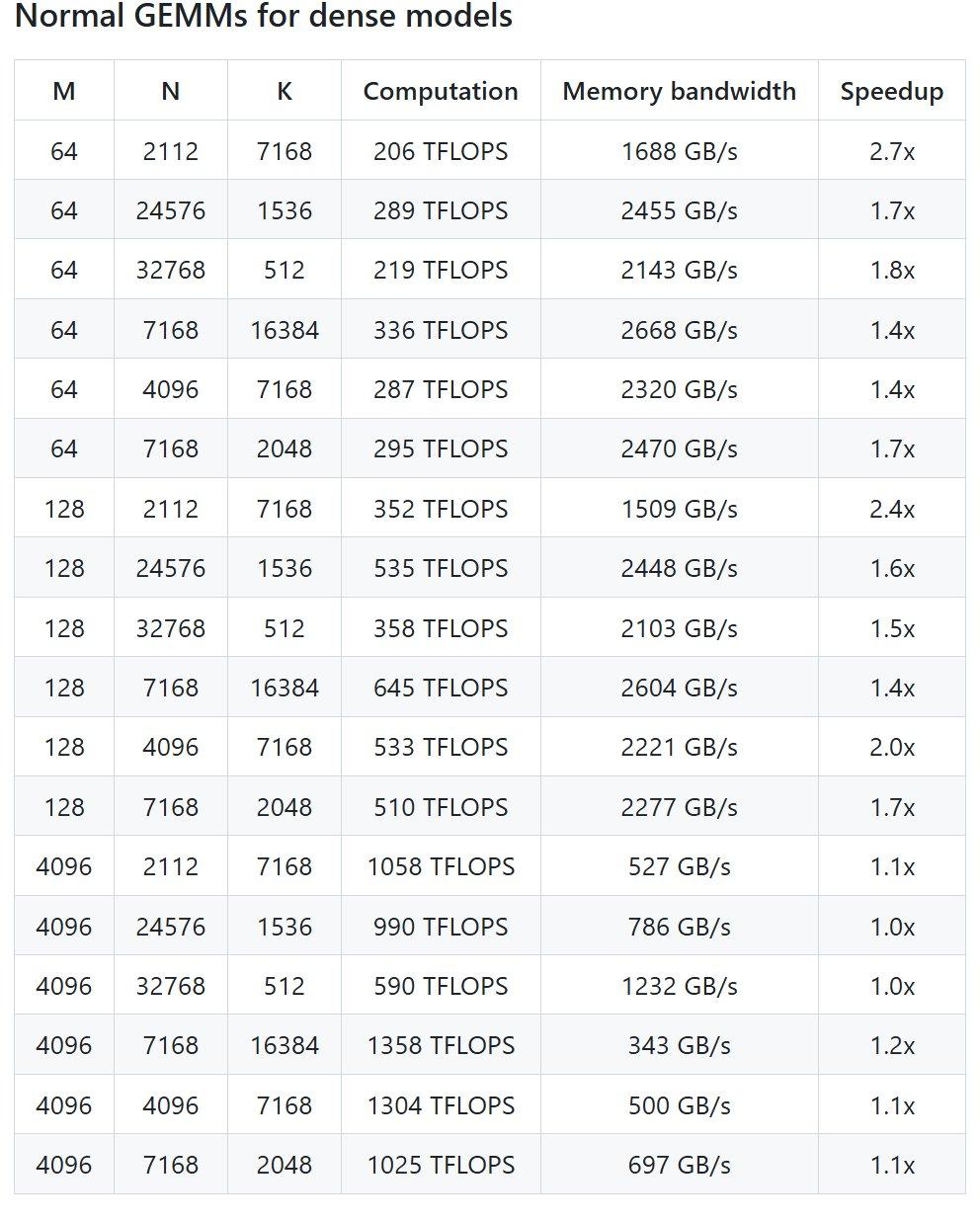
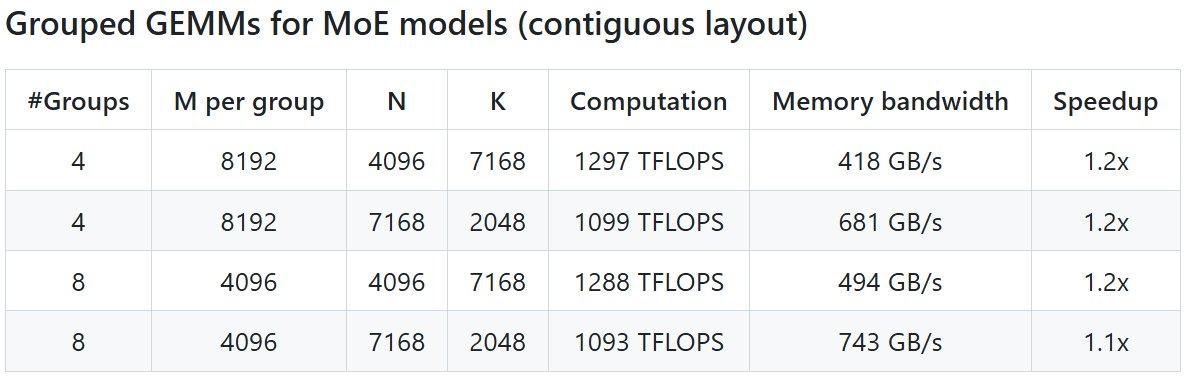
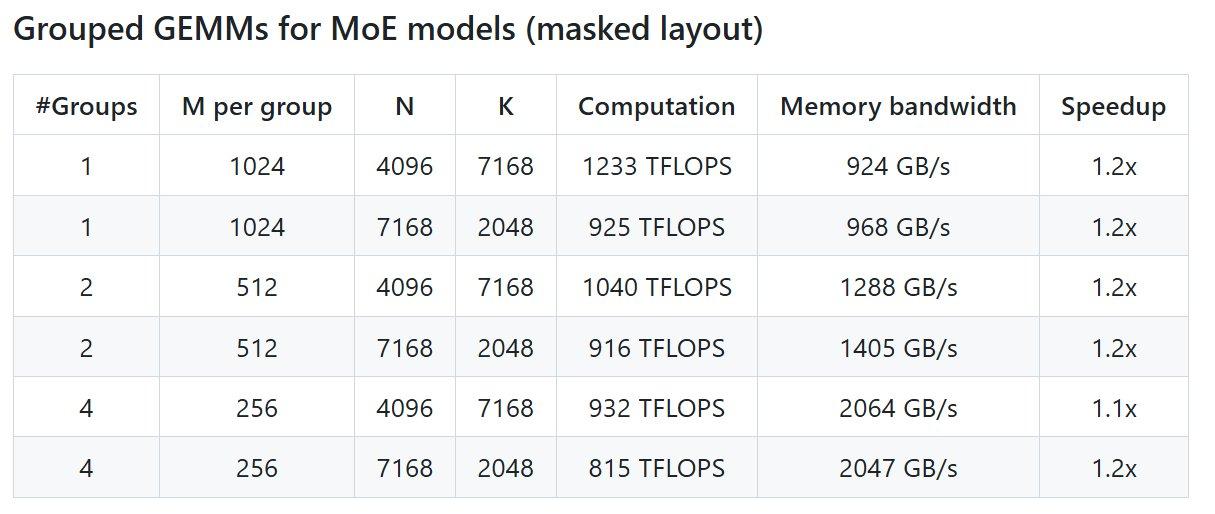
项目性能
本地搭建
-
Hopper 架构的 GPU,必须支持 sm_90a; -
Python 3.8 或更高版本; -
CUDA 12.3 或更高版本,但为了获得最佳性能,DeepSeek 强烈推荐使用 12.8 或更高版本; -
PyTorch 2.1 或更高版本; -
CUTLASS 3.6 或更高版本(可通过 Git 子模块克隆)。
# Submodule must be cloned
git clone --recursive git@github.com:deepseek-ai/DeepGEMM.git
# Make symbolic links for third-party (CUTLASS and CuTe) include directories
python setup.py develop
# Test JIT compilation
python tests/test_jit.py
# Test all GEMM implements (normal, contiguous-grouped and masked-grouped)
python tests/test_core.py
#install 安装
python setup.py install