11 月 22 日,Prime Intellect 宣布通过去中心化方式训练完成了一个 10B 模型。30 号,他们开源了一切,包括基础模型、检查点、后训练模型、数据、PRIME 训练框架和技术报告。据了解,这应该是有史以来首个以去中心化形式训练得到的 10B 大模型。
技术报告:https://github.com/PrimeIntellect-ai/prime/blob/main/INTELLECT_1_Technical_Report.pdf
Hugging Face 页面:https://huggingface.co/PrimeIntellect/INTELLECT-1-Instruct
GitHub 地址:https://github.com/PrimeIntellect-ai/prime
体验链接:chat.primeintellect.ai
测试1:英语短句理解能力
测试2:英语长句理解能力
测试3:中文短句理解能力
测试4:中文长句理解能力
测试5:中英混合短句理解能力
测试6:中英混合长句理解能力
大规模去中心化训练
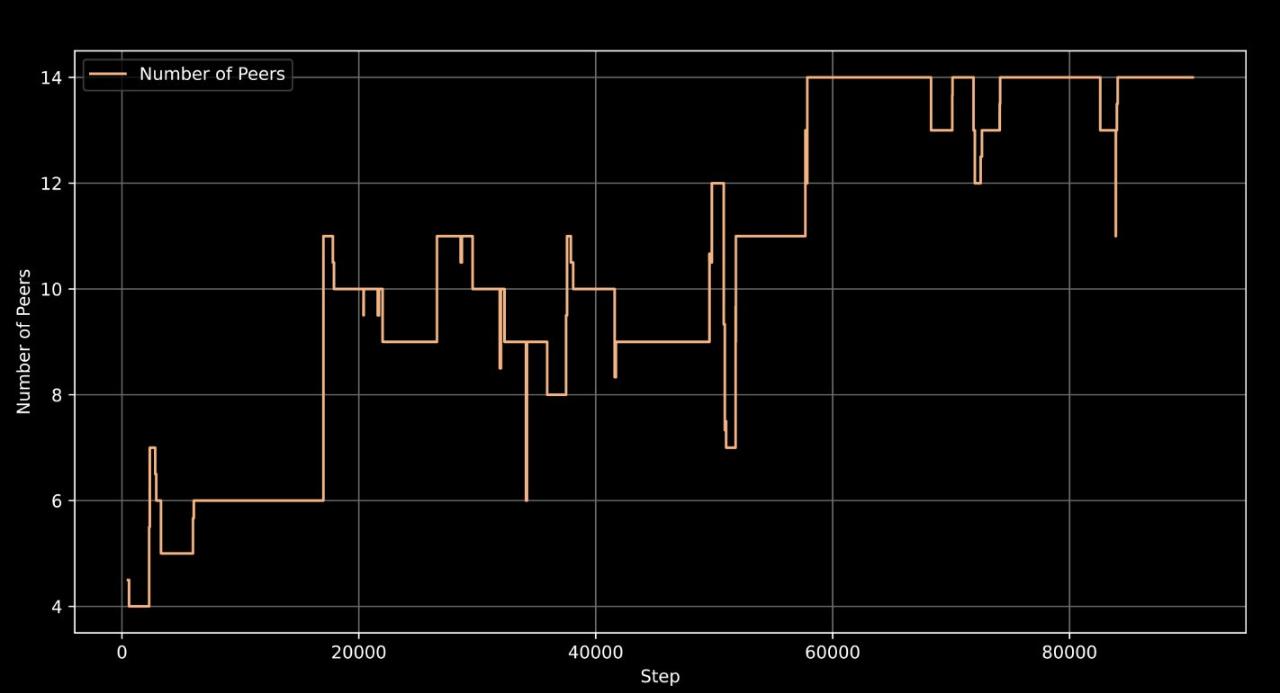
Prime Intellect 的这场去中心化训练的规模其实相当大,涉及到 3 个大洲的 5 个国家,同时运行了 112 台 H100 GPU。该团队表示:「我们在各大洲实现了 83% 的总体计算利用率。当仅在分布于整个美国的节点上进行训练时,实现了 96% 的计算利用率。与中心化训练方法相比,开销极小。」
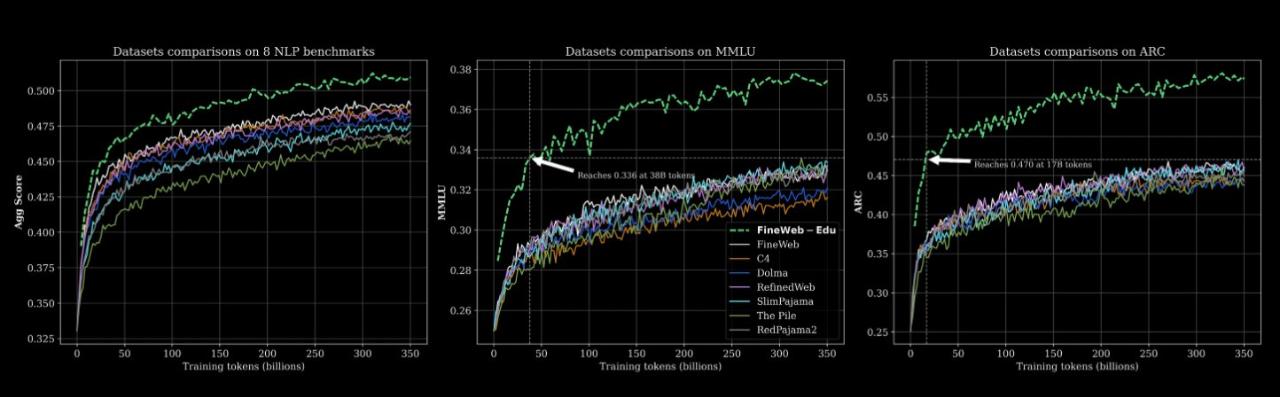
数据集 Huggingface 链接:https://huggingface.co/datasets/HuggingFaceFW/fineweb-edu
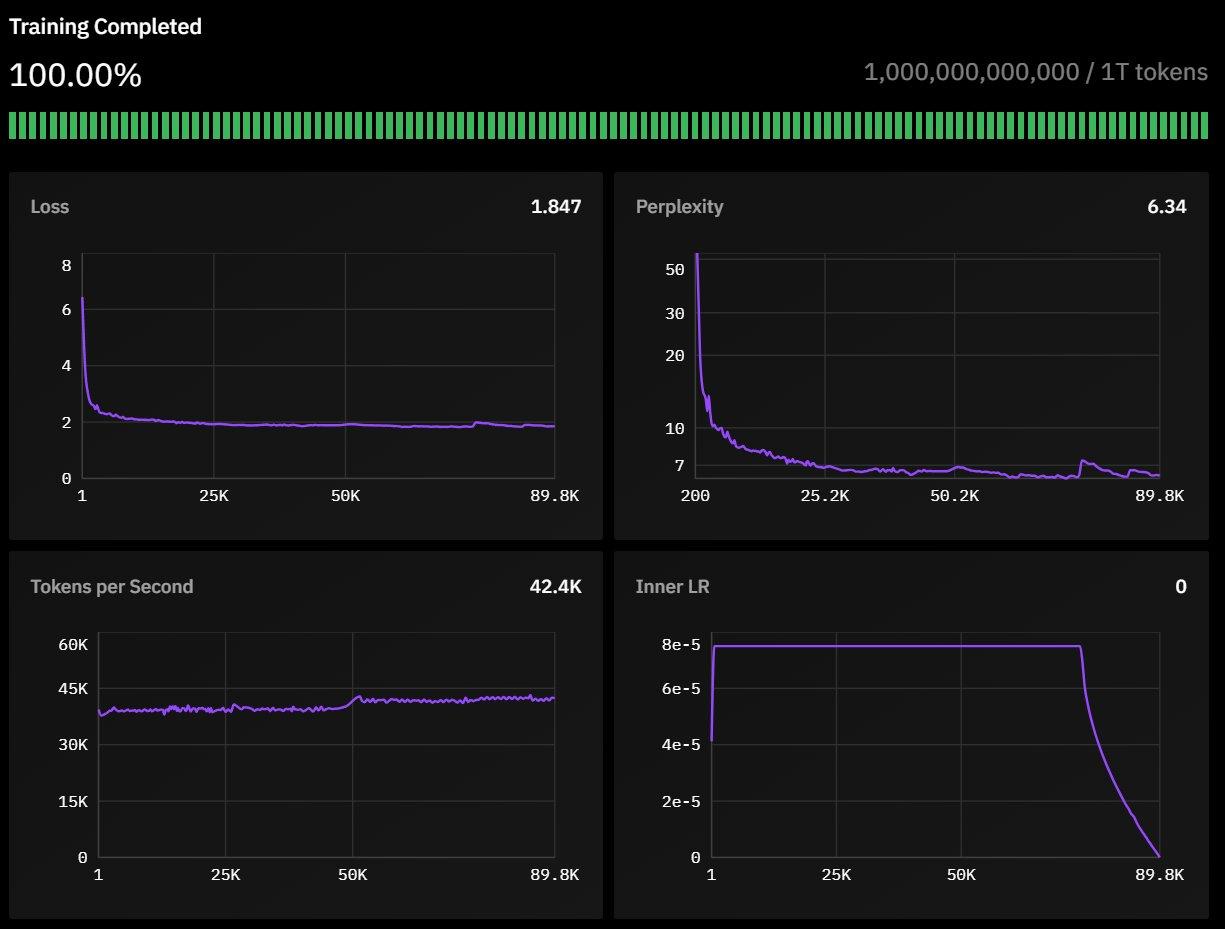
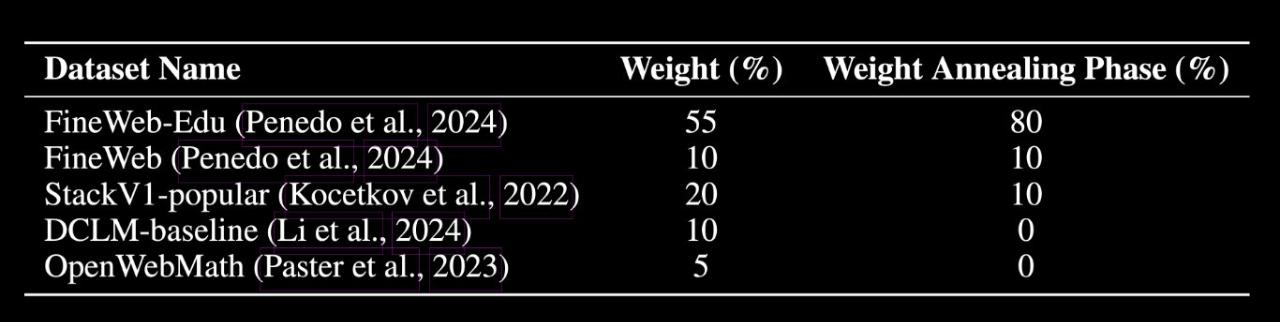
模型在经过精心筛选的 1 万亿 token 数据集上训练,数据构成如下:
- 55% FineWeb-Edu
- 20% Stack v2(Stack Overflow 等技术问答数据)
- 10% FineWeb(精选网页数据)
- 10% DCLM-baseline(基准通用语料)
- 5% OpenWebMath(数学数据)
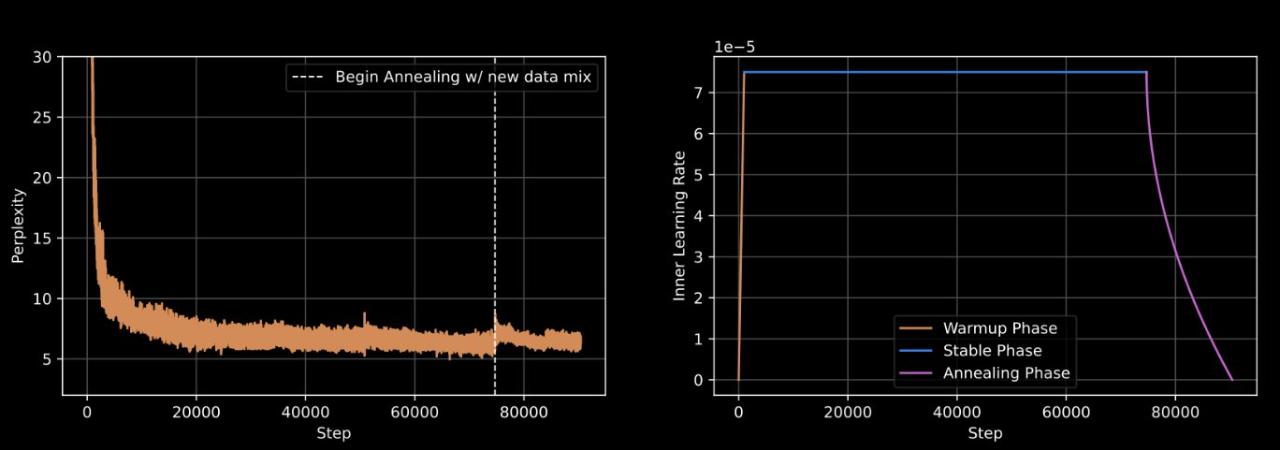
- 采用 WSD 动态调整学习速度,让模型学习更高效
- 精细调教的学习参数:内层学习率设为 7.5e-5
- 引入特殊的损失函数(max-z-loss)来确保训练过程的稳定性
- 使用 Nesterov 动量优化算法,帮助模型更快更好地学习
- 支持训练机器的灵活接入和退出,最多可同时使用 14 台机器协同训练
Prime框架分析
该团队使用的训练框架名为 Prime,这基于他们开发的 OpenDiLoCo。而 OpenDiLoCo 又基于 DeepMind 之前开发的 Distributed Low-Communication(DiLoCo)方法。
项目地址:https://github.com/PrimeIntellect-ai/OpenDiLoCo

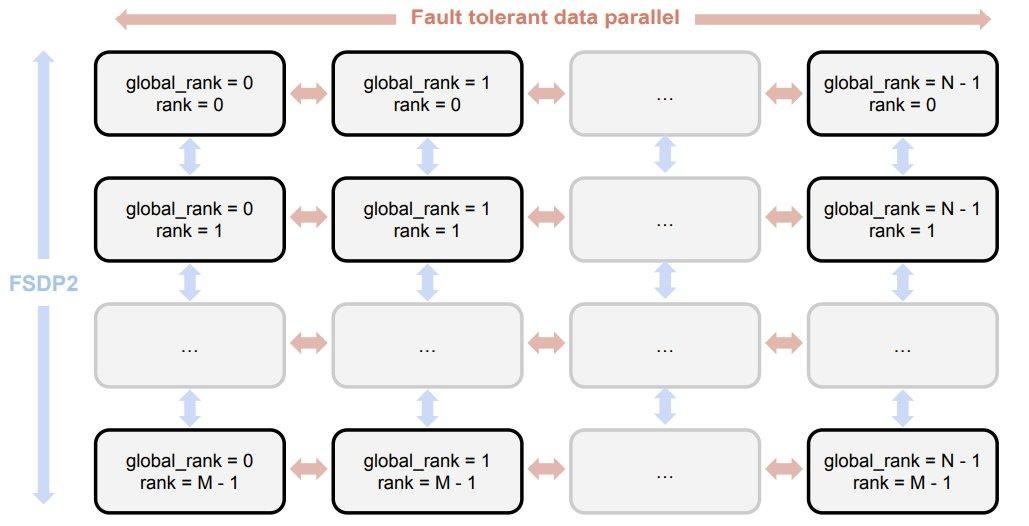
该团队在博客中写道:「该框架构成了我们开源技术堆栈的基础,其目标是支持我们自己的算法以及 OpenDiLoCo 之外的其他去中心化训练算法。通过在此基础架构上构建,我们的目标是突破全球分布式 AI 训练的极限。」
具体来说,Prime 框架包含以下关键特性:
-
用于容错训练的 ElasticDeviceMesh -
异步分布式检查点 -
实时检查点恢复 -
自定义 Int8 All-Reduce 内核 -
最大化带宽利用率 -
PyTorch FSDP2 / DTensor ZeRO-3 实现 -
CPU 卸载
计算效率分析

后训练
在完成分布在全球的预训练阶段后,Prime Intellect 与 Arcee AI 合作开展了一系列后训练,以提升 INTELLECT-1 的整体能力和特定任务表现。主要包含三个阶段:
-
SFT(监督微调,16 轮) -
DPO(直接偏好优化,8 轮) -
使用 MergeKit 整合训练成果
其他方面分析
论文链接:https://github.com/PrimeIntellect-ai/prime/blob/main/INTELLECT_1_Technical_Report.pdf
未来目标
-
继续扩大全球计算网络 -
用更多奖金激励推动社区参与 -
进一步优化 PRIME 去中心化训练架构以支持更大的模型