
由于大模型技术的快速进步,人们对 AI 解决数学问题的能力寄予厚望,第一届 AIMO 的获奖队伍分获了 104.8 万美元的奖金,而现在第二届,奖池已经上升到了 211.7 万美元。AIMO 竞赛要求参赛团队公开发布其代码、方法、数据和模型参数。刚刚结束的第一届比赛里大家使用的模型各不相同,包括 Mixtral 8x7b、Gemma、Llama 3 等等,有的来自大厂,有的来自 AI 创业公司,呈现百花齐放的态势。
HuggingFace 开源地址:https://huggingface.co/Qwen/QwQ-32B-Preview
HuggingFace Space 体验:https://huggingface.co/spaces/Qwen/QwQ-32B-preview
据介绍,QwQ(Qwen with Questions)是通义千问 Qwen 大模型最新推出的实验性研究模型,也是阿里云首个开源的 AI 推理模型。阿里云通义千问团队研究发现,当模型有足够的时间思考、质疑和反思时,其对数学和编程的理解就会深化。基于此,QwQ 取得了解决复杂问题的突破性进展。
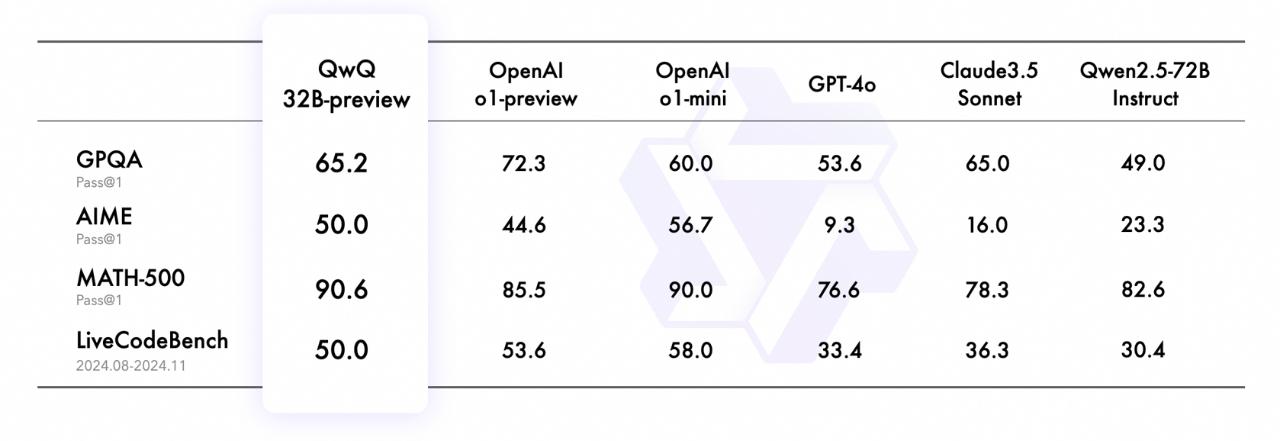
在考察科学问题解决能力的 GPQA 评测集上,QwQ 获得了 65.2% 的准确率,具备研究生水平的科学推理能力;在涵盖综合数学主题的 AIME 评测中,QwQ 以 50% 的胜率证明其拥有解决数学问题的丰富技能;在全面考察数学解题能力的 MATH-500 评测中,QwQ 斩获 90.6% 的高分,一举超越了 o1-preview 和 o1-mini;在评估高难度代码生成的 LiveCodeBench 评测中,QwQ 答对一半的题,在编程竞赛题场景中也有出色表现。另外当面对复杂问题时,QwQ 展现了深度自省的能力,会质疑自身假设,进行深思熟虑的自我对话,并仔细审视其推理过程的每一步。
比如,在经典智力题「猜牌问题」中,QwQ 会通过梳理各方对话并推演现实情况,它像个擅长思考的人一样,能揣摩「这句话有点 tricky」,反思「等一下,也许我需要更仔细地思考」,最终分析得出正确答案,这似乎是以前没有 AI 能做到的事情。面对目前高涨的热度,通义团队表示,尽管 QwQ 展现了强大的分析能力,但该模型仍是个供研究的实验型模型,存在不同语言的混合使用、偶有不恰当偏见、对专业领域问题不了解等局限。随着研究深入模型迭代,这些问题将逐步得到解决。
模型架构分析
从这个架构参数来看,QwQ-32B-Preview与Qwen2.5-32B非常接近。那么大概率是模型的训练数据有了很大的变化。QwQ-32B-Preview主要通过详细和自省的方式来解决问题,具体表现为:
-
多步骤推理:,QwQ-32B-Preview不直接给出结论,而是通过一个类似人类的思考过程,逐步推导出解决方案。它会考虑不同的可能性、采取不同的策略,并且在过程中进行反思和调整。这种方式模仿了人类在面对复杂问题时的思考模式,即非直线型的探索和调整。
-
自省:QwQ-32B-Preview在推理过程中会对自己采取的策略和步骤进行自我检查和反思。通过不断地评估当前的推理路径,模型能够做出更合理的调整。这类似于人类在思考时会时常停下来反思自己的推理是否合理。
总的来说,QwQ-32B-Preview的这种推理方式看起来更像是“思考”的过程,而不是简单的“回答”。它更注重推理的过程,而不仅仅是给出答案,这与传统的模型输出直接答案的方式有所不同。
模型测评结果
QwQ-32B-Preview模型在推理能力方面效果显著,即使与GPT-4o、Claude Sonnet 3.5和Qwen2.5-72B比较也是非常优秀的。
GPQA:研究生级Google-Proof问答基准,这是一个通过小学级问题评估科学问题解决能力的具有挑战性的基准。
AIME:美国数学邀请赛,测试包括算术、代数、计数、几何、数论和概率在内的中学数学主题的数学问题解决能力。
MATH-500:MATH基准的500个测试用例,一个全面测试数学问题解决能力的数据集。
LiveCodeBench:一个在真实世界编程场景中评估代码生成和问题解决能力的具有挑战性的基准。
基于上面的评测结果我们可以看到:QwQ 32B-preview在数学推理和复杂问题求解方面表现出色,但在对编程任务的处理能力上相对较弱。与OpenAI的模型相比,QwQ 32B-preview在一些任务(如GPQA)中的表现处于中等水平,虽然不如OpenAI的最强模型,但也展现出了强大的潜力。AIME分数的表现显示其在多任务处理上有较好的均衡性。总的来说,QwQ 32B-preview适合在需要数学推理和数据分析的任务中使用,但对于编程任务,可能需要进一步的优化。
局限和挑战
Qwen团队也很坦诚地指出了QwQ 32B-preview模型的局限性,主要包括:
-
语言混合:模型可能会在处理语言时出现不同语言的混合。比如在多语言环境下,QwQ可能无法始终准确地区分语言边界,导致其输出中出现语言切换不当的问题。这通常是因为多语言模型在跨语言推理时可能无法有效地处理上下文或语境的转换。
-
递归推理的风险:递归推理是指模型在推理过程中反复调用自身的逻辑步骤,形成闭环或无限循环的过程。如果模型在推理时没有有效的终止机制,就可能导致推理过程陷入无休止的递归中。这不仅会浪费计算资源,还可能导致错误的推理结果。
-
需要进一步完善安全机制:在当前版本中,QwQ的安全机制可能存在漏洞,可能会被恶意用户利用进行不正当操作。比如,用户可能通过引导模型进入某些危险或不安全的推理路径,造成系统的不稳定或错误行为。因此,研究团队意识到需要加强模型的安全性,避免潜在的滥用。
-
常识推理的提升空间:尽管QwQ能够进行复杂的推理,但在常识推理方面,模型仍然存在一些不足。常识推理通常涉及对日常生活中的基本理解,而当前模型在这一方面可能缺乏足够的准确性,导致在一些常见场景中无法做出符合人类常识的反应。
实际测试表现
我给出几组用户连续2个月的不同的电信业务使用情况,然后问,哪个用户使用的业务量下降最多。这个问题其实很复杂,也缺少明确的含义。原因是考虑业务使用下降需要考虑不同业务的差异,下降最多其实是可以有多个不同的答案的,而且语音下降10分钟和流量下降1GB是不能简单一起对比的。QwQ 32B-preview对于这个问题的解答给了两个逻辑,第一个是把每个业务下降的数值求和(显然不合理),然后觉得不好,又计算不同业务下降百分比,然后求和,但是不管怎么说似乎都不对,最后模型给出建议是当前情况: