
论文标题:BiGR: Harnessing Binary Latent Codes for Image Generation and Improved Visual Representation Capabilities
论文链接:https://arxiv.org/pdf/2410.14672
代码与模型:https://github.com/haoosz/BiGR
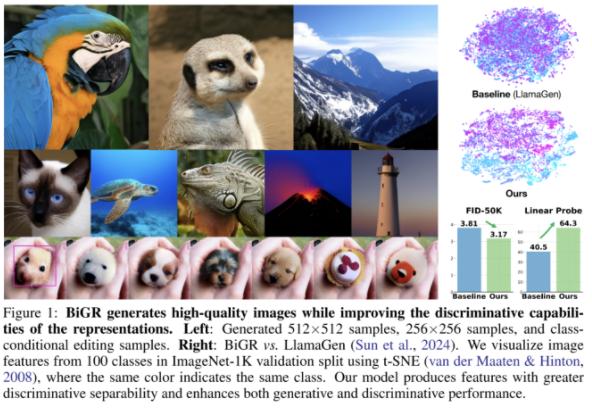
这些工作为研究界继续探索自回归模型在视觉领域的 Scaling Law 提供了一些启发。在这篇文章中,我们将对这些工作进行深入解读。顺带一提,这两项研究的代码和模型都已发布。研究者提出了 BiGR,一种条件图像生成模型,利用紧凑的二进制潜在编码实现生成与判别的统一。模型由二进制 tokenizer、掩码建模机制和转码器构成,并采用熵排序采样提高生成效率。大量实验表明,BiGR 在图像质量(FID-50k)和表示能力(线性探针准确率)上均表现出色,具备零样本泛化能力,可应用于图像修复、扩展、编辑、插值、增强及文本到图像生成,为相关领域开辟了新途径。
图像生成正处于由扩散模型与自回归模型驱动的快速发展期。尽管这些模型在生成质量上表现出色,其表示能力却长期被忽视。正如 Balestriero & LeCun (2024) [1] 指出,基于重建的学习方法虽可生成视觉效果良好的图像,但难以提供有力的潜在表示能力。研究界一直期望构建一个既能生成图像、又能作为强特征提取器的图像生成器。
现有关于表示能力的研究大多集中在无条件生成模型上,尽管条件生成模型近年来逐渐受到关注,但对其表示能力的研究仍然有限。在条件生成中,模型通过条件信息引导生成过程;但这种引导在下游判别任务中无法延续,从而削弱了特征与类别之间的联系,影响表示质量。我们使用最新的类条件图像生成模型验证了这一局限性,并强调提升其表示能力的必要性。
模型框架分析
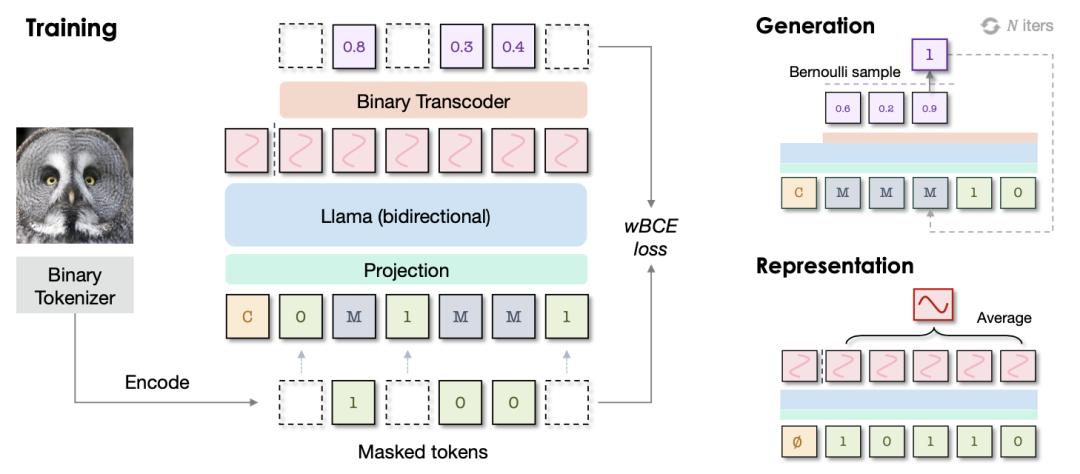
我们提出了BiGR,一种新型的条件图像生成模型,采用紧凑的二进制潜在编码,旨在同时提升生成与表示能力。BiGR 不依赖判别损失,仅通过重建 token 的方式进行训练。我们使用 lookup-free 量化方法 [2,3] 将图像编码为二进制序列,并训练模型预测这些二进制代码。BiGR 是首个将生成与判别任务统一于一个框架的条件生成模型,在多个基准任务上都表现优异。
BiGR 的模型架构基于语言模型,包含三个核心组件:(1) 二进制tokenizer:将像素级图像转为二进制潜在代码序列;(2) Transformer 编码器:具备全双向注意力;(3) 二进制转码器:将连续特征映射为伯努利分布下的二进制代码。我们采用 masked 建模方法训练模型,不改变语言模型结构的基础上增强 token 间交互,从而支持生成与判别任务的统一建模。
在生成任务中,BiGR 采用基于二进制熵排序的采样策略,按伯努利分布的熵值大小逐步解码 token,仅需少量采样迭代,显著加速推理过程。相比多步去噪的扩散模型,该方法在效率与质量上均具优势,实验证明其性能可媲美甚至超越现有基线。
在判别任务中,我们对 BiGR 的中间特征执行平均池化。实验表明,该方法在无需复杂结构的前提下即可实现强表示能力,并通过线性探针验证其特征可有效区分类别。这得益于二进制编码的紧凑性和掩码建模带来的全局上下文信息。
此外,BiGR 还展现出出色的零样本泛化能力。得益于掩码机制在推理阶段的高度灵活性,BiGR 无需结构或参数调整即可适配不同视觉任务,实现如图像修复、外扩、编辑、插值、增强等多种应用。我们还扩展 BiGR 至文本到图像生成任务,进一步证明其广泛的实用潜力。
BiGR的优势
- 一致性(Uniformity) —— BiGR 是首个在同一模型中统一生成任务与判别任务的条件图像生成模型。通过建模紧凑的二进制潜在编码,BiGR 在这两类任务中均展现出优于现有模型的强大性能。
- 高效性(Efficiency) —— BiGR 以较低的时间成本生成图像,这得益于在迭代解码过程中所需采样步骤的数量较少,同时仍能保持较高的生成质量。
- 灵活性(Flexibility) —— BiGR 可灵活地应用于多种视觉任务,如图像修复、外扩、编辑、插值和增强等,并能以零样本方式执行,无需特定任务的结构性更改或参数微调。
- 可扩展性(Scalability) —— BiGR 在生成与判别任务中均展现出良好的可扩展性,这一点通过生成质量和线性探针性能的全面评估得到了验证。
前置知识
- 二进制tokenizer(binary tokenizer)
- 伯努利扩散过程(Bernoulli diffusion process)
二进制tokenizer(Binary tokenizer):略
伯努利扩散(Bernoulli diffusion):略
二进制编码的掩码建模
主干网络:方法基于 Transformer 架构的语言模型 LLaMA构建。与语言不同,图像并不天然地适合被建模为一个因果的 token 序列。相反,为了更好地捕捉全局信息,每一个 token 都应能够访问其他所有 token。在视觉信息中,我们用双向注意力替换语言模型中常用的因果注意机制,让模型预测被掩码的 token,而非下一个 token。
输入投影:在输入空间中,我们不再查表获得嵌入向量,而是使用一个简单的线性层,将二进制代码投影到嵌入空间。这种技术最近在连续tokenzier中得到了验证,我们发现其对二进制tokenizer也同样有效。我们保留了标准条件嵌入和掩码嵌入,其中条件嵌入被加在序列的开头,掩码嵌入则替代了被掩码的位置。
掩码 token 预测:训练过程中,对图像 token 的一部分进行掩码,使用可学习的掩码矩阵M。掩码 token 遵循余弦调度策略。只对被掩码位置进行损失计算,也就是模型需要预测其值的位置。
二进制解码器:掩码 token 遵循余弦调度策略。我们只对被掩码位置进行损失计算,也就是模型需要预测其值的位置。
视觉显示:一旦训练完成,我们的模型能够学习强大的视觉表示。给定一个图像,我们输入其未被掩码的版本,以及附加的无条件 token。我们在连续值特征 h上执行平均池化,以表示整个图像。我们观察到,最具判别力的表示并非来自 Transformer 的最后一层,而是中间层特征,这与之前工作的发现一致。因此,我们使用中间特征进行下游任务。
熵排序生成采样
为了图像生成,给模型设计了一种采样策略,使其能够从完全掩码的序列中逐步预测 token。与训练阶段不同的是,训练时的掩码位置是随机选择的,而在采样阶段,token 的解码顺序遵循预设的准则。根据预测概率计算出的二进制熵大小,对被掩码的 token 进行排序。