在最近关于「Scaling Law 是否撞墙」的讨论中,后训练(post-training)被寄予厚望。众所周知,近期发布的 OpenAI o1 在数学、 代码、长程规划等问题上取得了显著提升,而背后的成功离不开后训练阶段强化学习训练和推理阶段思考计算量的增大。基于此,有人认为,新的扩展律 —— 后训练扩展律(Post-Training Scaling Laws) 已经出现,并可能引发社区对于算力分配、后训练能力的重新思考。不过,对于后训练到底要怎么做,哪些细节对模型性能影响较大,目前还没有太多系统的资料可以参考,因为这都是各家的商业机密。曾经重新定义「开源」并发布了史上首个 100% 开源大模型的艾伦人工智能研究所(Ai2)站出来打破了沉默。他们不仅开源了两个性能超过 Llama 3.1 Instruct 相应版本的新模型 ——Tülu 3 8B 和 70B(未来还会有 405B 版本),还在技术报告中公布了详细的后训练方法。
在提升模型性能方面,后训练的作用越来越大,具体包括微调和 RLHF 等。此前,OpenAI、 Anthropic、Meta 和谷歌等大公司已经大幅提升了其后训练方法的复杂度,具体包括采用多轮训练范式、使用人类数据 + 合成数据、使用多个训练算法和训练目标。也正因为此,这些模型的通用性能和专业能力都非常强。但遗憾的是,他们都没有透明地公开他们的训练数据和训练配方。到目前为止,开源后训练一直落后于封闭模型。在 LMSYS 的 ChatBotArena 排行榜上,前 50 名(截至 2024 年 11 月 20 日)中没有任何一个模型发布了其后训练数据。即使是主要的开放权重模型也不会发布任何数据或用于实现这种后训练的配方细节。Tülu 3 模型之外,Ai2 还发布了所有的数据、数据混合方法、配方、代码、基础设施和评估框架!
模型:https://huggingface.co/allenai
技术报告:https://allenai.org/papers/tulu-3-report.pdf
数据集:https://huggingface.co/collections/allenai/tulu-3-datasets-673b8df14442393f7213f372
GitHub:https://github.com/allenai/open-instruct
Demo:https://playground.allenai.org/
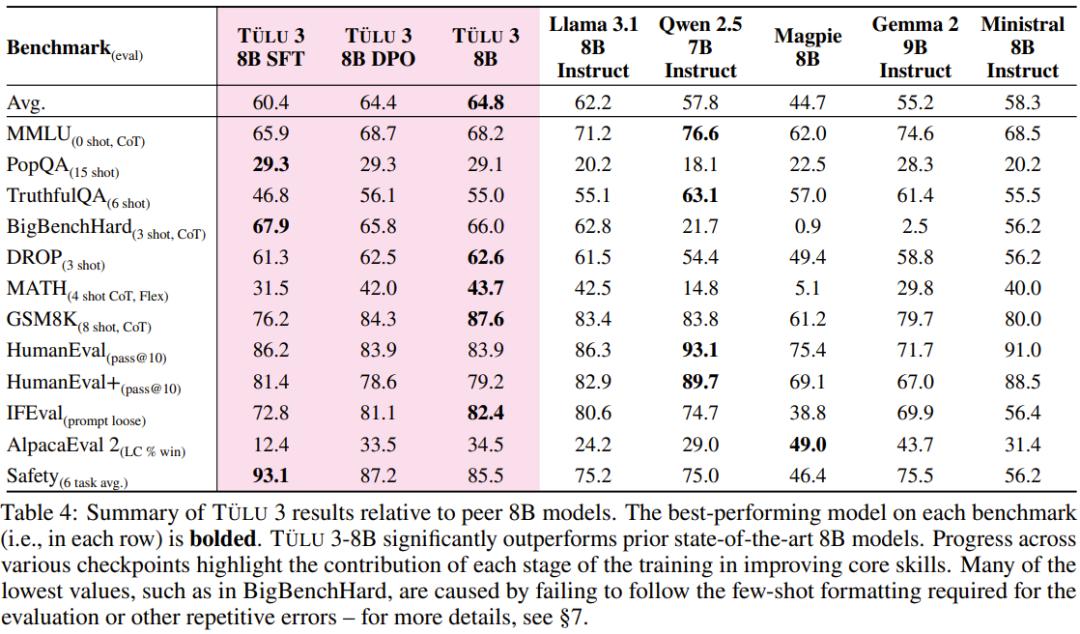
模型、数据集、代码分析:
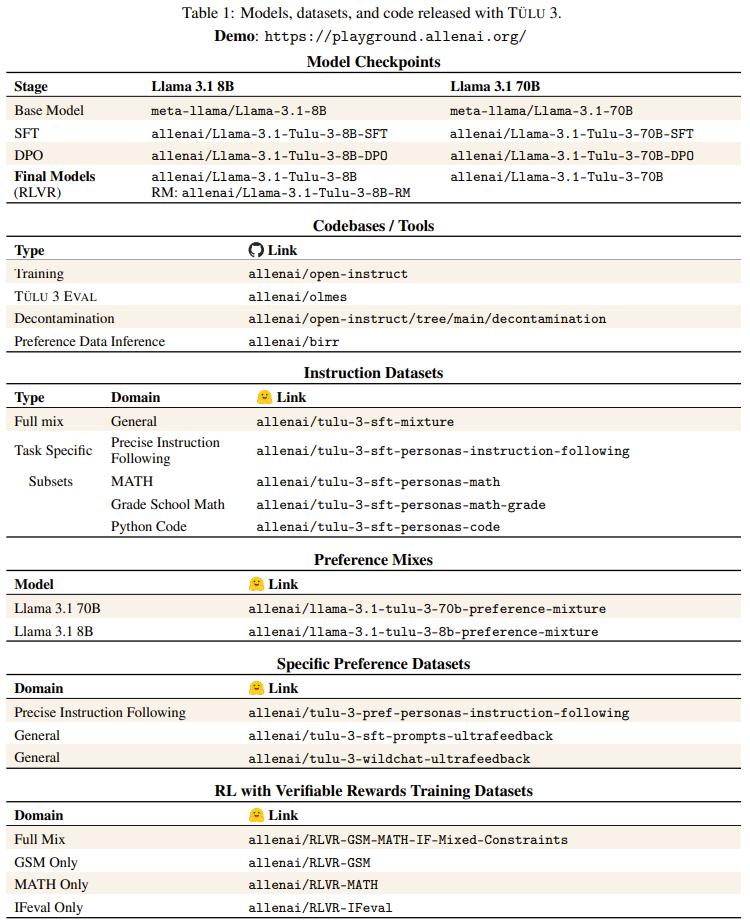
这是70B的表现:
Tulu3模型框架分析
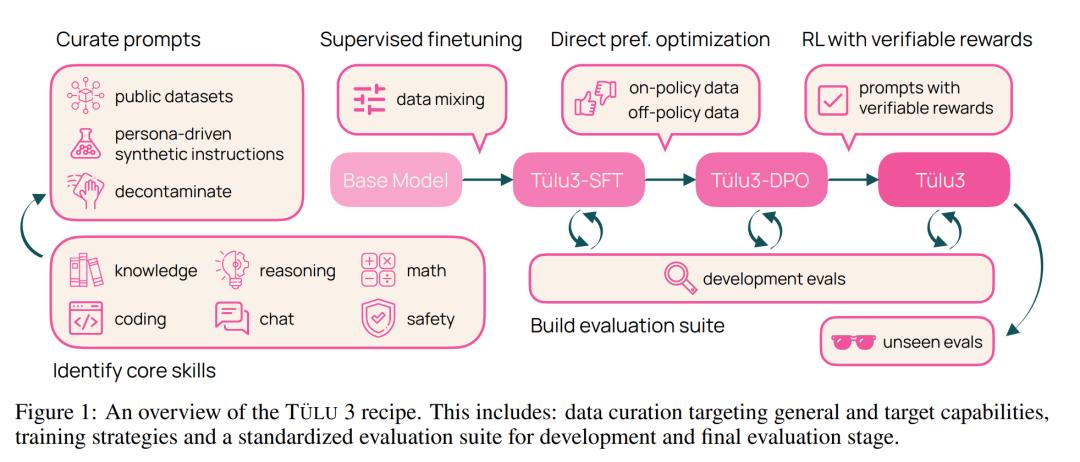
阶段一:数据整理。Ai2 整理了各种提示(prompt)信息,并将其分配到多个优化阶段。他们创建了新的合成提示,或在可用的情况下,从现有数据集中获取提示,以针对特定能力。他们确保了提示不受评估套件 Tülu 3 EVAL 的污染。
阶段二:监督微调。Ai2 利用精心挑选的提示和回答结果进行监督微调(SFT)。在评估框架指导下,他们通过全面的实验,确定最终的 SFT 数据和训练超参数,以增强目标核心技能,同时不对其他技能的性能产生重大影响。
阶段三:偏好微调。Ai2 将偏好微调 —— 特别是 DPO(直接偏好优化)—— 应用于根据选定的提示和 off-policy 数据构建的新 on-policy 合成偏好数据。与 SFT 阶段一样,他们通过全面的实验来确定最佳偏好数据组合,从而发现哪些数据格式、方法或超参数可带来改进。
-
阶段四:具有可验证奖励的强化学习。Ai2 引入了一个新的基于强化学习的后训练阶段,该阶段通过可验证奖励(而不是传统 RLHF PPO 训练中常见的奖励模型)来训练模型。他们选择了结果可验证的任务,例如数学问题,并且只有当模型的生成被验证为正确时才提供奖励。然后,他们基于这些奖励进行强化学习训练。
Tulu3的主要贡献
-
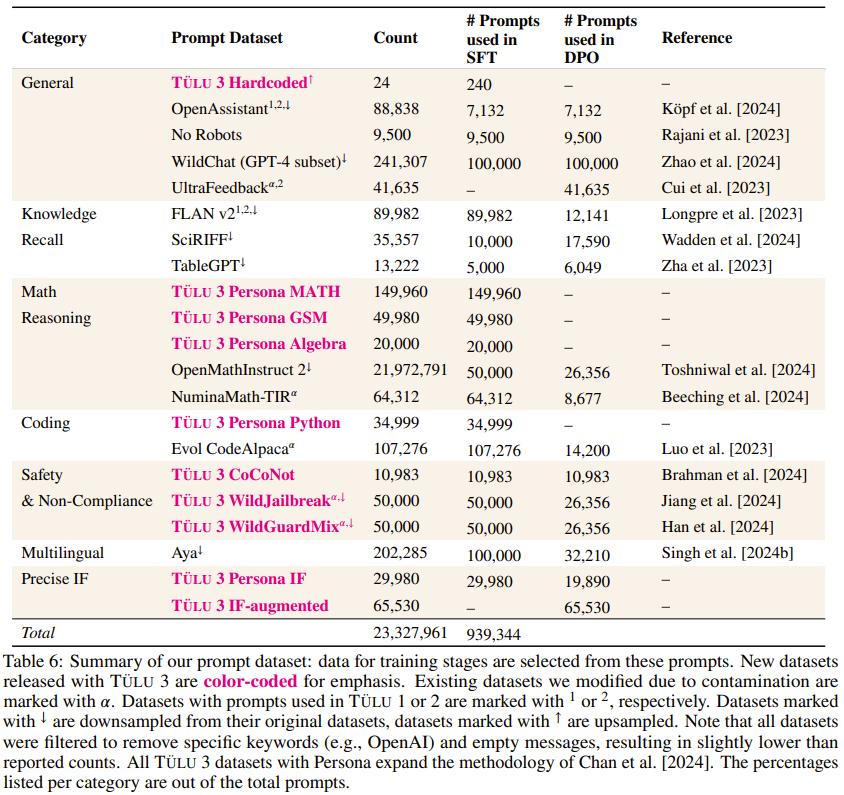
数据质量、出处和规模:Ai2 通过仔细调查可用的开源数据集、分析其出处、净化来获取提示,并针对核心技能策划合成提示。为确保有效性,他们进行了全面的实验,研究它们对评估套件的影响。他们发现有针对性的提示对提高核心技能很有影响,而真实世界的查询(如 WildChat)对提高通用聊天能力很重要。利用 Tülu 3 EVAL 净化工具,他们可以确保提示不会污染评估套件。
-
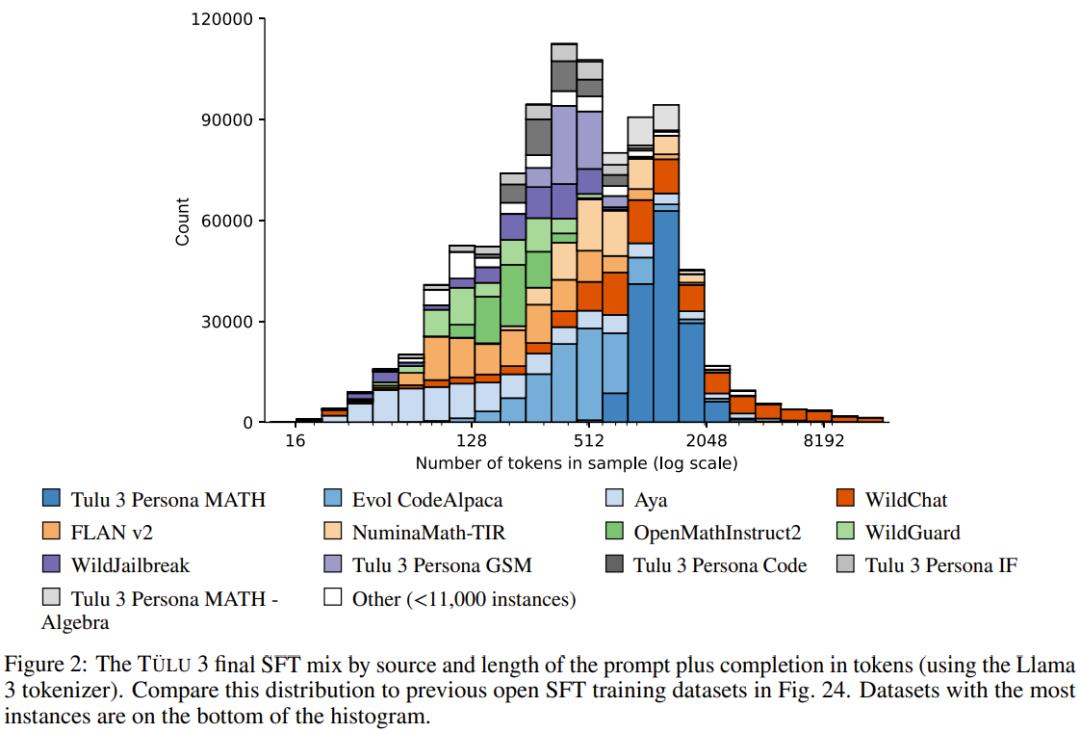
创建多技能 SFT 数据集。通过利用不同数据混合结果进行几轮有监督微调,Ai2 优化了「通用」和「特定技能」类别中提示的分布。例如,为了提高数学推理能力,Ai2 首先通过创建数学专业模型在评估套件中建立一个上限,然后混合数据,使通用模型更接近这个上限。
-
编排一个 On-Policy 偏好数据集。Ai2 开发了一个 on-policy 数据编排 pipeline,以扩展偏好数据集生成。具体来说,他们根据给定的提示从 Tülu 3-SFT 和其他模型中生成完成结果,并通过成对比较获得偏好标签。他们的方法扩展并改进了 Cui et al. [2023] 提出的 off-policy 偏好数据生成方法。通过对偏好数据进行精心的多技能选择,他们获得了 354192 个用于偏好调整的实例,展示了一系列任务的显着改进。
-
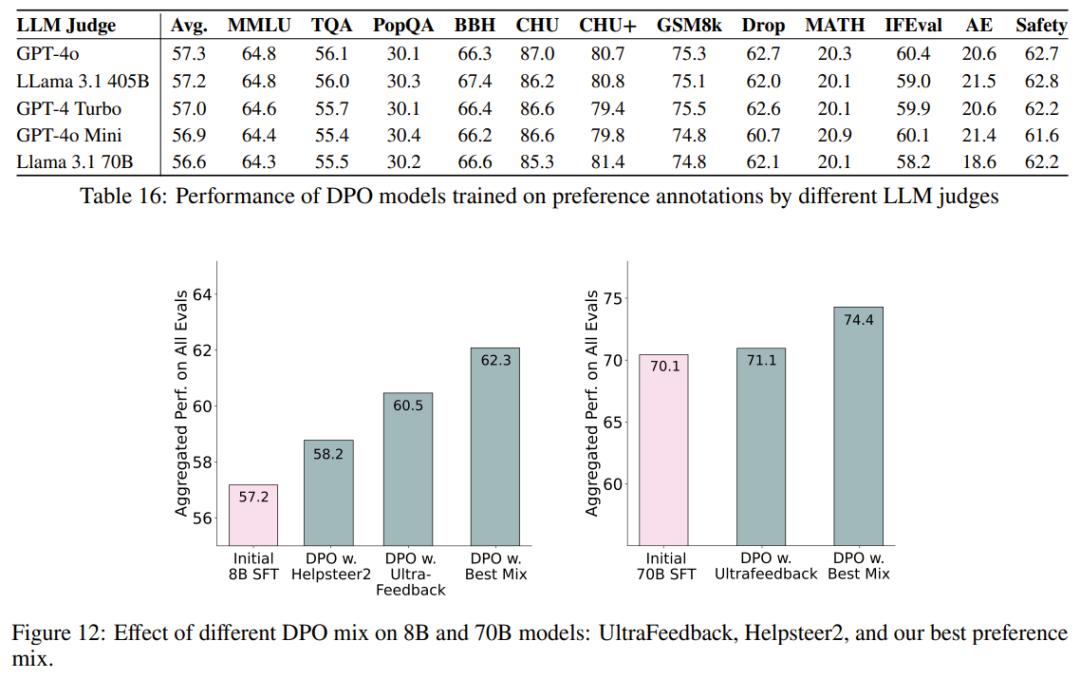
偏好调整算法设计。Ai2 对几种偏好调整算法进行了实验,观察到使用长度归一化( length-normalized)直接偏好优化的性能有所提高。他们在实验中优先考虑了简单性和效率,并在整个开发过程和最终模型训练中使用了长度归一化直接偏好优化算法,而不是对基于 PPO 的方法进行成本更高的研究。
-
具有可验证奖励的特定技能强化学习。Ai2 采用了一种新方法,利用标准强化学习范式,针对可以对照真实结果(如数学)进行评估的技能进行强化学习。他们将这种算法称为「可验证奖励强化学习」(RLVR)。结果表明,RLVR 可以提高模型在 GSM8K、MATH 和 IFEval 上的性能。
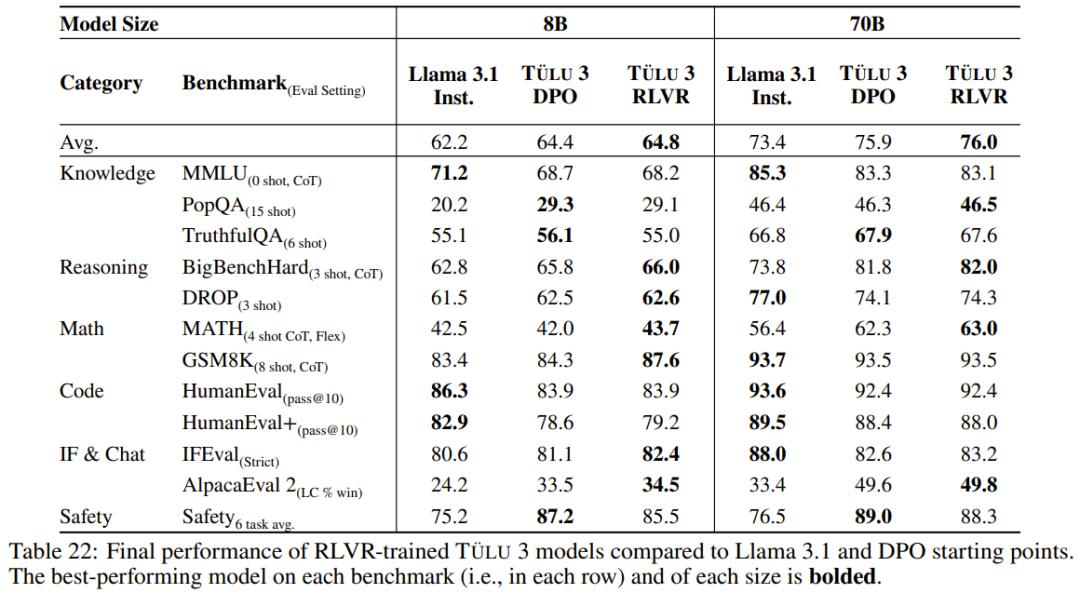
- 用于强化学习的训练基础设施。Ai2 实现了一种异步式强化学习设置:通过 vLLM 高效地运行 LLM 推理,而学习器还会同时执行梯度更新。并且 Ai2 还表示他们的强化学习代码库的扩展性能非常好,可用于训练 70B RLVR 策略模型。
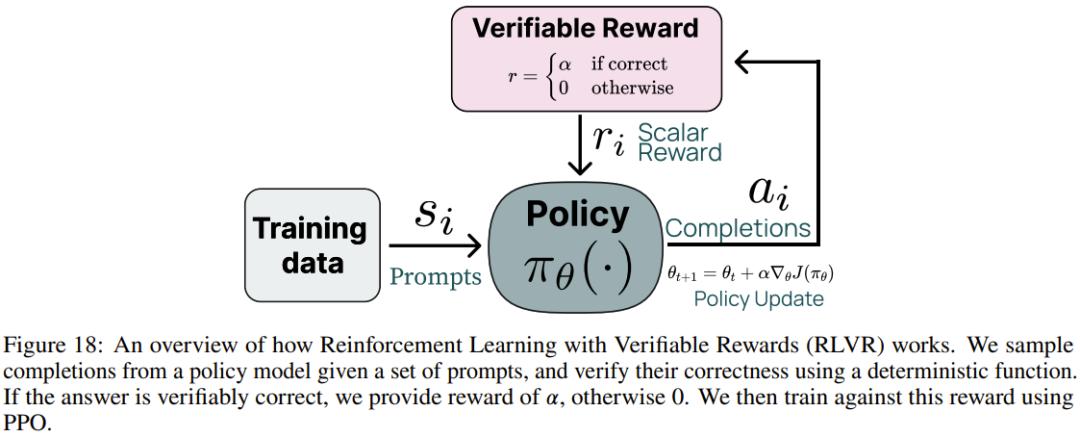
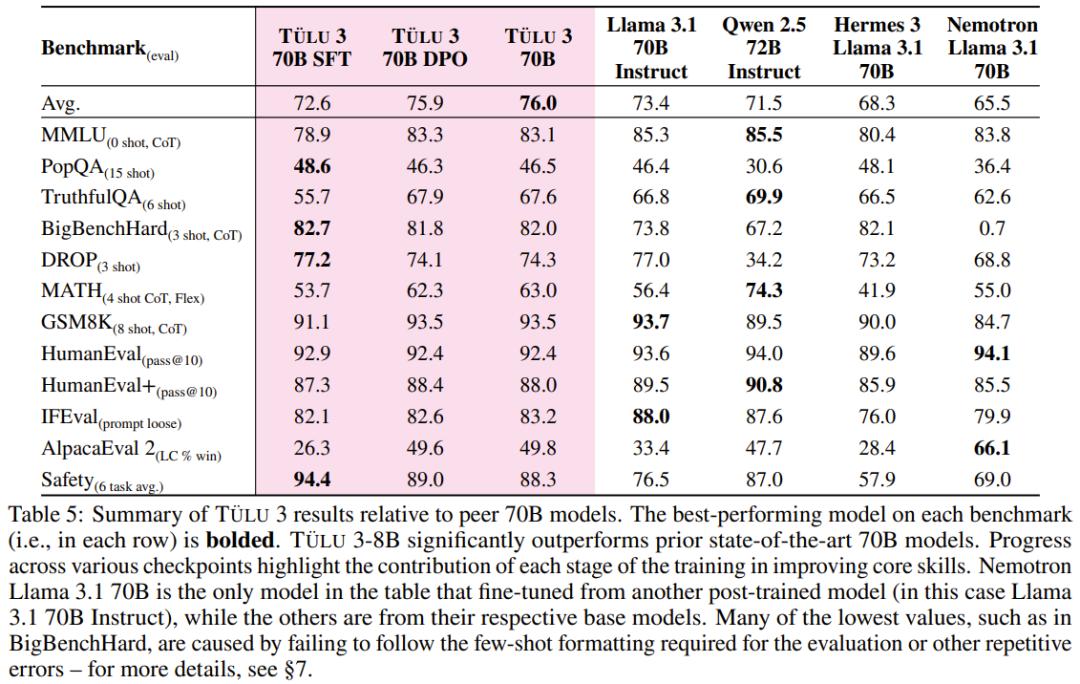
Tulu3模型性能表现
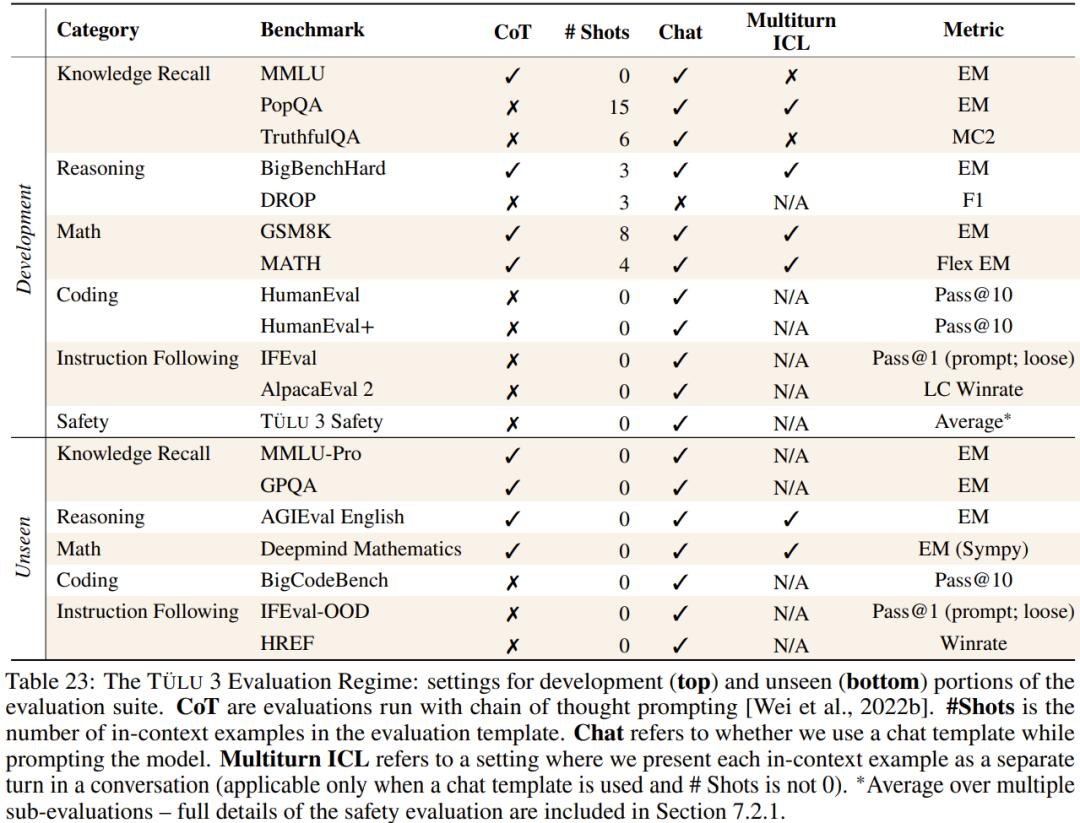
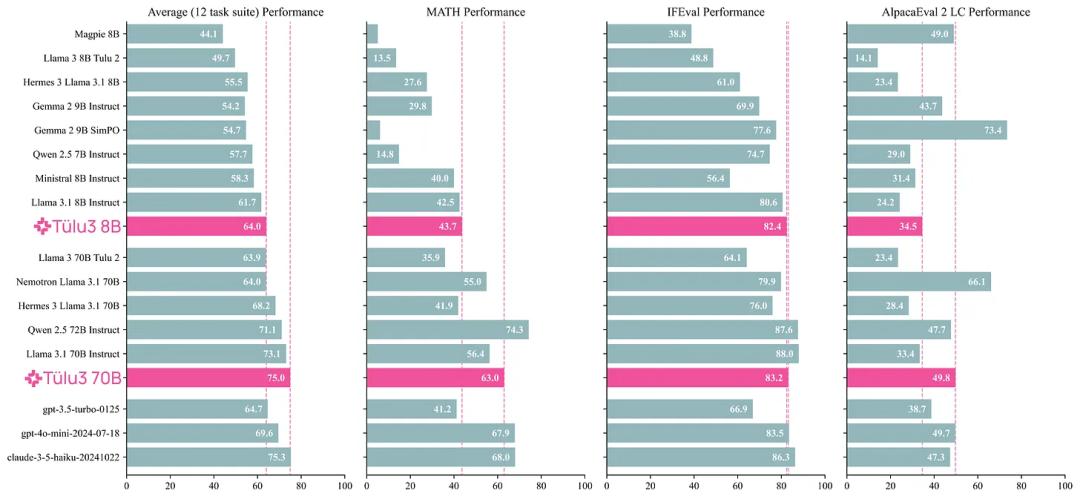
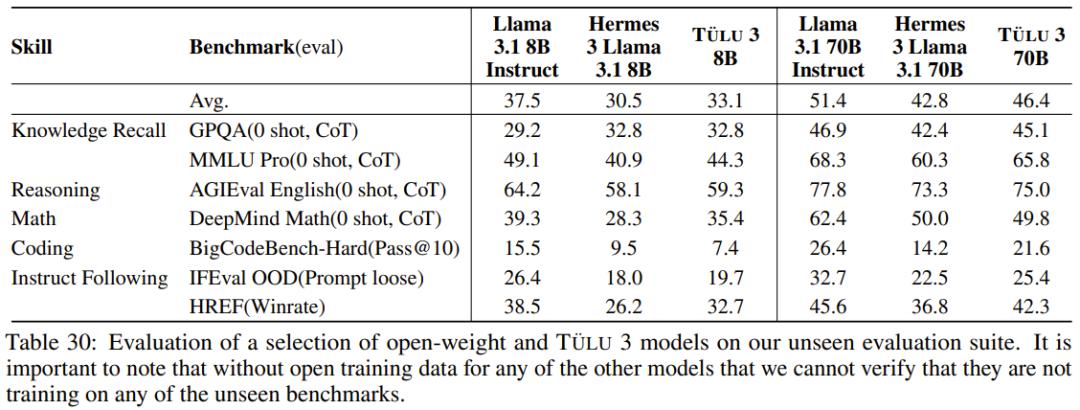
安全性方面,以下两表展示了 Tülu 3 与对比模型在两个基准上的安全分数。整体而言,同等规模下,Tülu 3 相较于其它开源模型更有优势。