无需人类背后操作,RDT 即可指挥机器人双臂并用,完美调出如晚霞般梦幻的鸡尾酒 Malibu Sunset。和人类调酒师一样,首先,RDT 将冰块稳稳倒入高脚杯中,不撒不漏,一套动作行云流水。倒完冰块后,RDT 先后倒入椰子酒、橙汁、菠萝汁,操作娴熟,顺序不乱,确保口味一致。注入石榴汁,晚霞般绚烂的酒红色在高脚杯中徐徐晕染开来。最后,RDT 发挥空间感,夹起一片柠檬,轻轻卡在有弧度的杯口上。
在领略了 RDT 的强大后,是时候揭开它的神秘面纱了 —— RDT 的全称是 Robotics Diffusion Transformer,是全球最大的针对双臂机器人操作任务的扩散基础模型,由清华大学人工智能研究院 TSAIL 团队构建。当前,机器人领域公认的卡脖子问题是 “不够智能”。许多模型需要人教几十遍才能完成单个任务,面对没教过的情况则 “束手无策”。
而 RDT 正是这个 “智能困境” 的破壁者之一。它为 ALOHA 硬件本体植入了 “小脑”,使其能摆脱人类的操控,自主完成没见过的任务。RDT 将 “小模型” 扩展为 “大模型”,从 “单臂” 变为 “双臂”,是目前运动控制水平最接近人类的机器人小脑之一。更惊喜的是,清华团队已将 RDT 的代码、模型,甚至训练它的双臂数据集彻底开源。他们坚信,开源 RDT 能极大加速机器人研发和产业化进程。
项目主页:https://rdt-robotics.github.io/rdt-robotics
论文链接:https://arxiv.org/pdf/2410.07864
论文标题:RDT-1B: a Diffusion Foundation Model for Bimanual Manipulation
模型分析
- 在机器人扩散模型中,RDT 拥有目前「最大的模型参数量」,高达 1.2B。比之前由谷歌、Deepmind 等牵头研发的最大的具身扩散模型(八爪鱼,Octo,93M)还要大一个数量级。
- RDT 在「最大的具身数据集」上预训练。预训练数据集包含 46 个不同的机器人数据集,总共有超过 100 万条人类演示数据。模型在 48 块 H100 显卡上预训练了 1M 步。
- RDT 拥有目前「最大的双臂微调数据集」。清华团队构建了包括 300+ 任务和 6K+ 条演示的数据集。与之对比,先前由斯坦福、MIT 等领衔研发的具身大模型 OpenVLA 的微调数据集仅有几百条演示。在大多数情况,人们会在日常生活中使用双手。机器人如果能像人一样挥动双臂,显然更灵活,也更能帮助人类
一是,在机器人领域,缺乏一个像 GPT 一样的通用、强大的「模型架构」。它不仅需要能学会各种的动作模式(modality),还需要具备可扩展性(scalability)。换言之,扩大模型的参数量,它的性能也要跟着一起涨。二是,在之前的研究中,尚没有一个公认的在多种机器人数据上训练的方案。这主要是因为不同机器人的硬件结构和传感器不同,进而导致数据的格式五花八门,难以进行统一的处理。在本文中,研究者通过提出创新型的多模态模型架构,以及统一的物理可解释动作空间,来解决这些挑战。
新架构分析
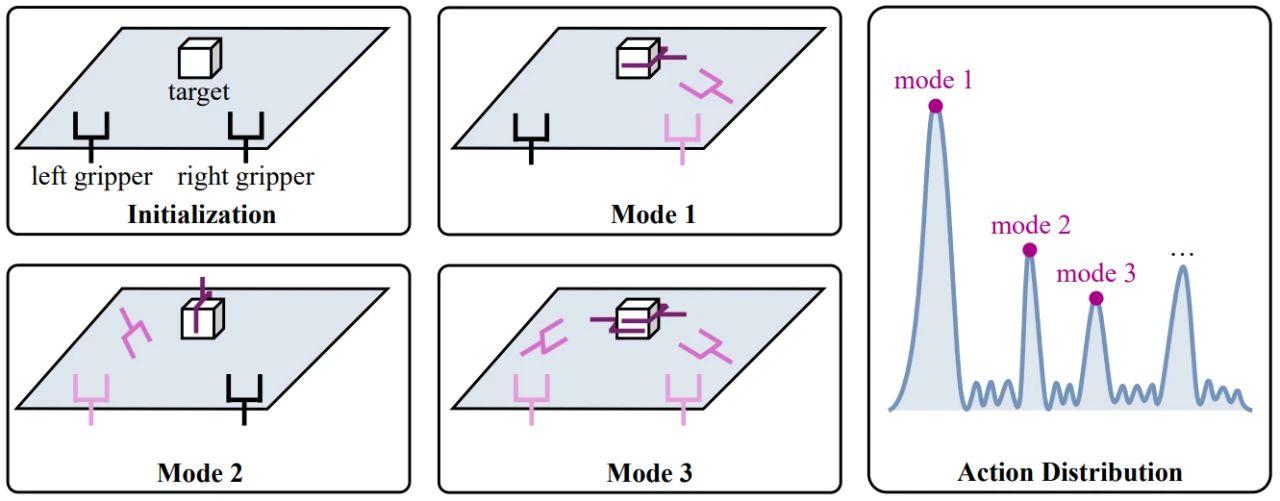
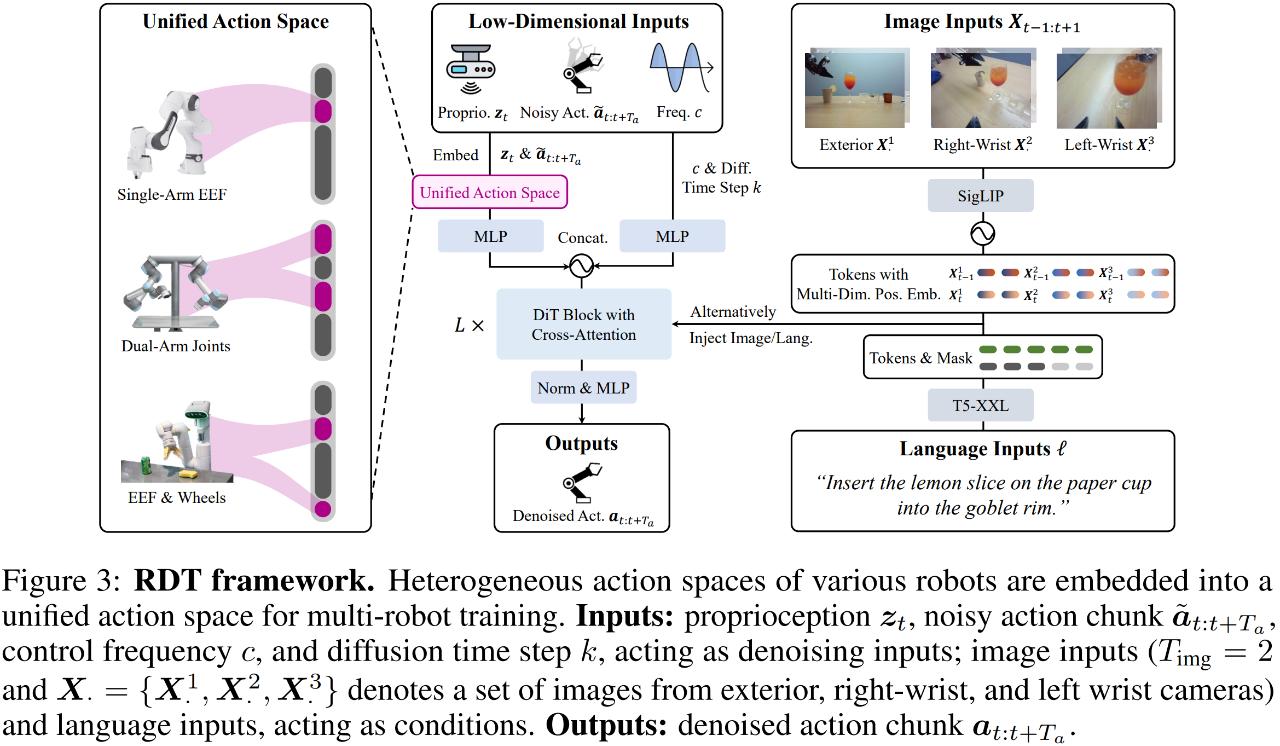
首先是多模态输入的编码。对于一个具体的机器人任务,模型在收到人类发出的语言指令后,需要结合自己的视觉观察,来预测完成任务所需的机械臂动作(action)。这里就涉及到了语言、图片和动作三种模态:
-
动作具有低维度和高频的特点。研究者采用具有傅里叶特征的多层感知机(MLP)来进行编码。
-
图片具有高维度的特点,同时含有丰富的空间和语义信息。研究者采用经过对齐的 SigLIP 进行编码。
-
语言具有变长的特点,并且高度抽象。研究者采用一个具有丰富知识的语言大模型 —— T5-XXL 来进行编码。
此外,不同模态包含的信息量不尽相同。咱们人都喜欢看信息量大的图而不喜欢看信息量小的文字。其实模型也一样。为了避免模型 “偷懒”,只看信息量大的模态,在训练中,研究者会以一定概率随机遮蔽(mask)各个模态。
网格结构
-
由于传感器失灵等原因,机器人数据中往往会出现极端值。这种极端值可能导致梯度不稳定和数值溢出等问题。研究者采用更加先进的 QKNorm 和 RMSNorm 来进行缓解。
-
机器人的动作往往符合非线性动力学的物理规律。为了增强对非线性的近似能力,研究者将最终层的线性解码器替换为非线性的 MLP 解码器。
-
图像的维度通常远高于文本的维度。同时将这两种模态注入到主干网络中时,往往图像会淹没文本,从而削弱模型的指令遵循能力。为此,研究者采取了交替注入的方式。
预训练和微调结合
为了在多种机器人数据上进行预训练,研究者需要对数据格式进行统一。具体来说,研究者构建了一个统一的动作空间(如图 3 左侧所示)。该空间的每个维度具有明确的物理含义,以保证模型能够从不同机器人数据中学习到共享的物理规律。在有了统一数据格式后,研究者就能将所有不同类型的机器人数据汇聚在一起,形成了目前最大的数据集,其包含超过 100 万条演示。正因为在如此大的数据集上进行预训练,RDT 获得了无与伦比的泛化性。最后,研究者还采集了目前质量最高的双臂微调数据集,用来微调 RDT 以增强其双臂操作能力。
数据集特点
-
数量大:6K+ 演示数据。
-
范围全:300+ 任务,从简单的抓取到精细操作,甚至包括黑板上解数学题一类的高难度操作。
-
多样性:100+ 不同类型的物体,15+ 不同的房间以及光照条件。
测试 RDT




A:可以。在洗杯子(Wash Cup)和倒水(Pour Water)任务中,RDT 对未见场景和物体仍能达到较高成功率,其表现与见过的情况相差不大。在 Pour Water-L-1/3 和 Pour Water-R-2/3 任务中,RDT 精确地理解了应该用哪只手操作、倒多少水,并能够严格遵循指令,即便它从未见过类似 “三分之一” 或 “三分之二” 这样的词汇。
A:可以。在物品传递(Handover)和折叠短裤(Fold Shorts)任务中,对于两个与已知动作模式完全不同的全新技能,RDT 仅分别通过 1 和 5 条演示的训练就轻松掌握,而其他方法几乎无法成功。
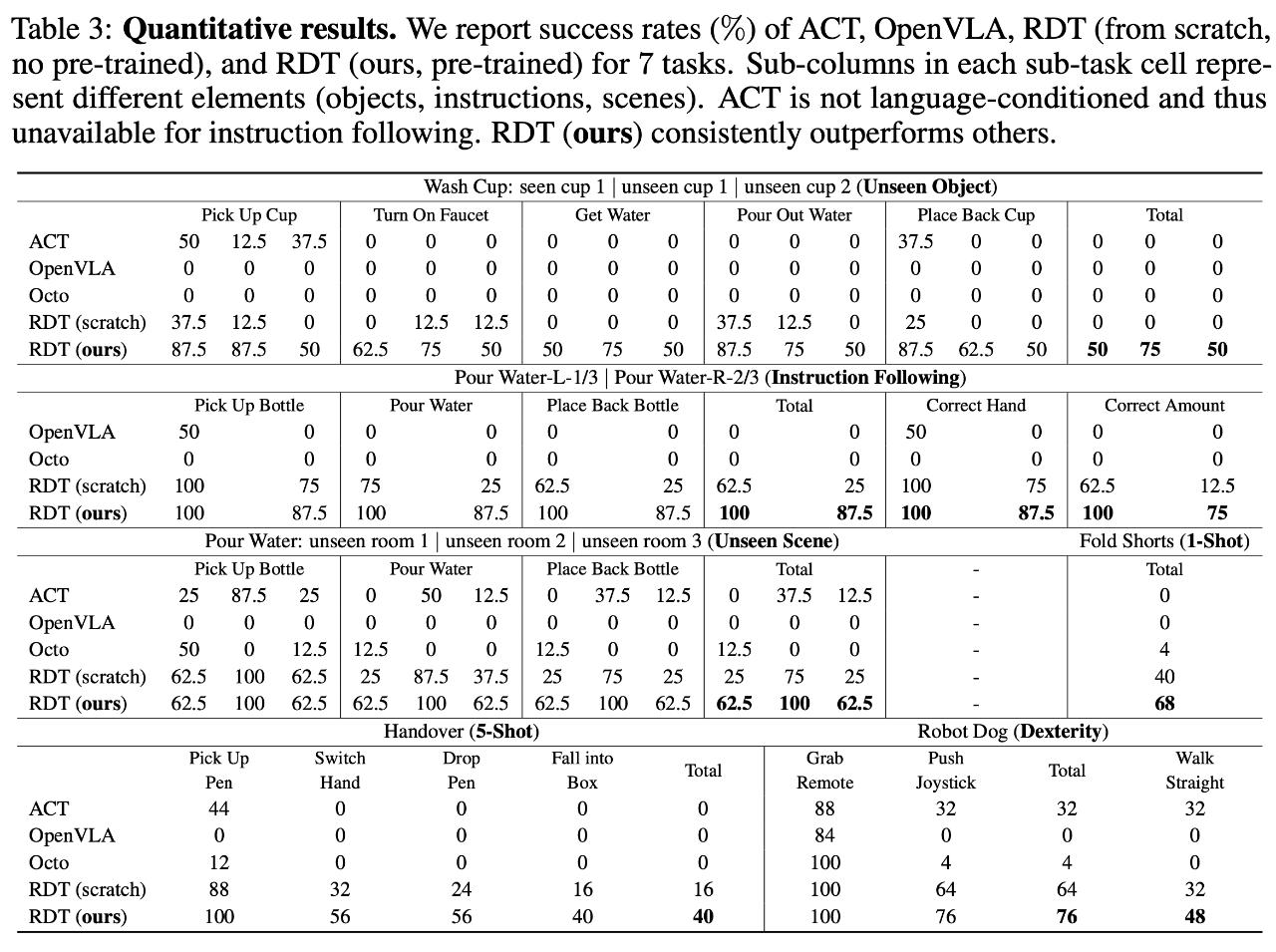
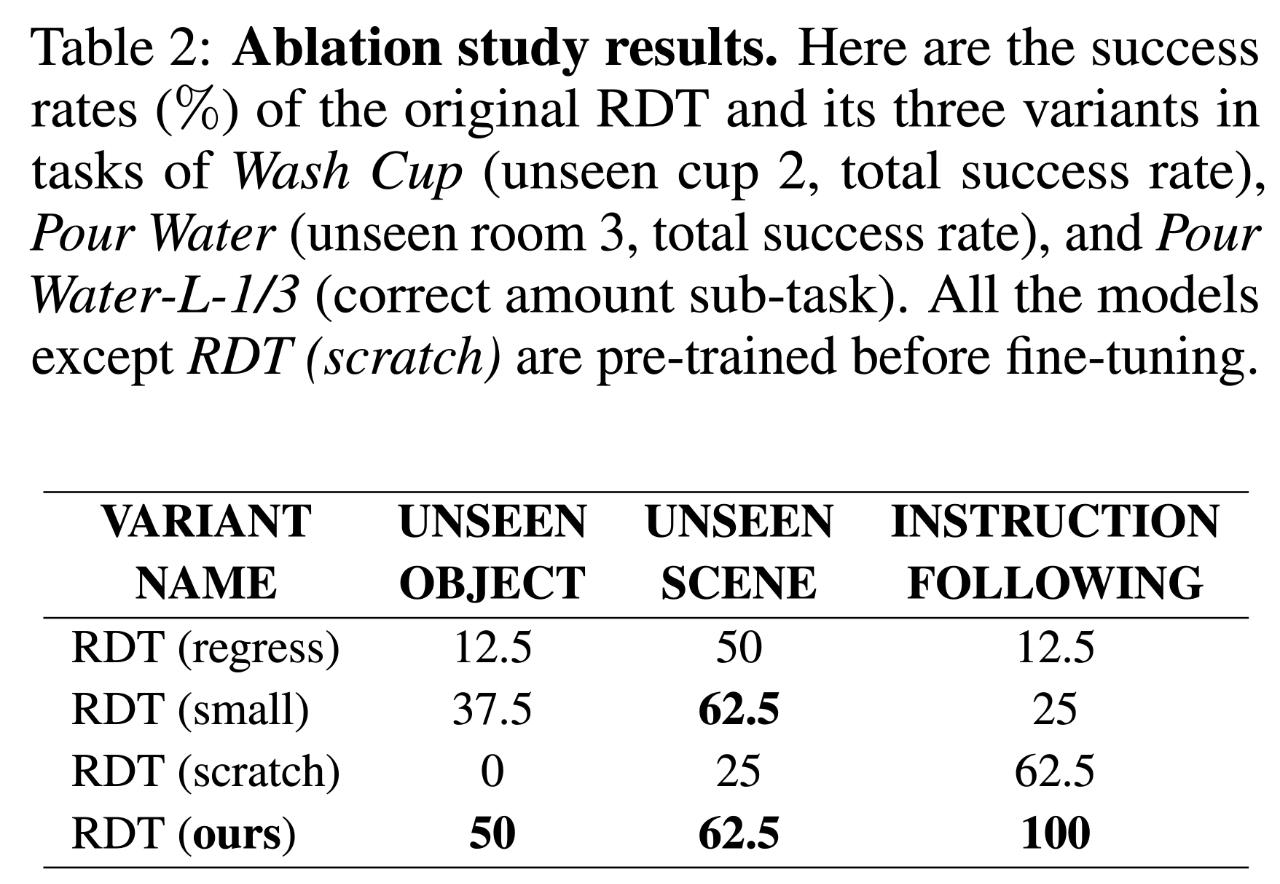
A:是的。如表 2 所示,研究人员对三者分别进行了消融实验,结果表明缺少任何一者都会带来极大的性能损失。特别地,仅用双臂数据训练的 RDT (scratch) 在未见物体和场景上表现极差,这表明预训练中学会的知识对于泛化性至关重要。