
随着对现有互联网数据的预训练逐渐成熟,研究的探索空间正由预训练转向后期训练(Post-training),OpenAI o1 的发布正彰显了这一点。而 Post-training 的核心在于评测(Evaluation)。可靠的 AI 评测不仅能在复杂任务的评测中提供可扩展的解决方案,减少人工劳动,还能在强化学习中生成有效的奖励信号并指导推理过程。例如,一个 AI 评测器可以遵循用户设计的评分标准,在视觉对话任务中为不同模型的回复(model response)提供 1 到 10 的评分。除了评分外,它还会提供相应的给分理由,确保模型性能评测的透明性和一致性。
来自字节跳动和马里兰大学的研究团队发布了首个用于多任务评测的开源多模态大模型 LLaVA-Critic,旨在启发社区开发通用大模型评测器(generalist evaluator)。
首先,该团队构建了一个涵盖了多样化评测场景和评分标准的评测指令遵循数据集(critic instruction-following dataset);之后,在这一数据集上训练 LLaVA-Critic,使之学会对模型回复给出合理评分(judgement)和打分依据(reason);更进一步,在多模态评测(LMM-as-a-Judge)和偏好学习(preference learning)两个场景中验证了 LLaVA-Critic 的有效性。
评测指令遵循数据集
- 单点评分(pointwise-scoring):根据评测提示,对单个模型回复进行打分。
- 成对排序(pairwise-ranking):对于两个(一对)模型回复,给出二者之间的偏序关系或宣布平局。

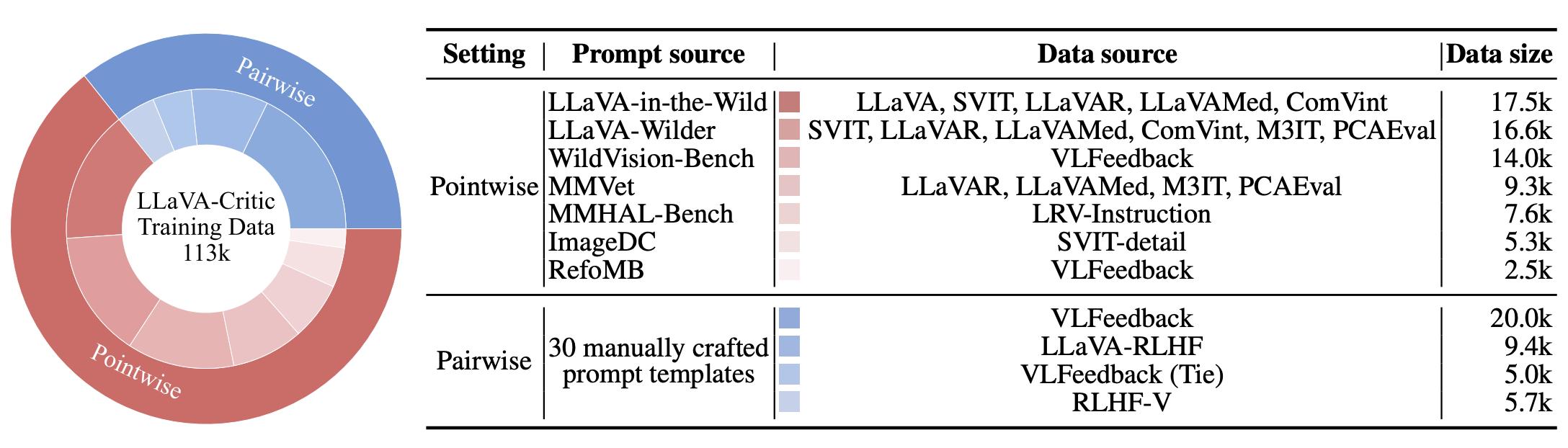
LLaVA-Critic-113k 主要包含单点评分和成对排序两种评测设定。在两种评测中,LLaVA-Critic 均需要根据给定的图片、问题、模型回复以及评测提示中给定的评分要求,对模型回复打分并给出理由。
针对单点评分,该团队从 8 个多模态数据集中收集了输入指令(图片 - 问题),使用 13 个 LMM 生成模型回复,并汇集了 7 个常用开放式评测基准中的评测提示,由此整理得到评测样本。针对于每一条评测样本,再询问 GPT-4o 进行评测,得到判断得分与理由。针对成对排序,该团队收集了三个偏好数据集中的模型回复,这些数据中已经包含了人类或 GPT-4V 的偏好排序结果。之后,将每一对模型回复和已知的偏序关系输入给 GPT-4o,获取其对偏序关系的解释。
在此基础上,他们设计了 30 个包含不同格式与评分标准的评测提示模板,将【图片 - 问题输入,两个模型回复,偏序关系,解释】打包成涵盖多种评测场景的评测指令遵循数据。由此,LLaVA-Critic-113k 数据集得以构建,共计包含 46k 张图片和 113k 个评测数据样本。下图展示了具体的数据统计:
LLaVA-Critic模型分析
为了使模型具备通用的评测能力,该团队对一个已经具备强大指令遵循能力的预训练多模态大模型进行指令微调。这一点非常关键,因为模型自身能高质量处理复杂视觉任务是其具备评测能力的基础;而评测能力则在此之上,作为附加的判别能力得到进一步开发。在训练中,LLaVA-Critic 会接受一个评测提示(evaluation prompt),包含多模态指令输入、模型回复及可选的参考回复。它会根据评测提示中的评分标准,预测定量分数或成对排序,并给出详细的理由。该团队对评测结果(分数或偏序关系)和理由同时应用交叉熵损失进行训练。实验中,他们从 LLaVA-OneVision (OV) 7B/72B 预训练模型开始,使用 LLaVA-Critic-113k 数据集进行 1 轮微调,得到 LLaVA-Critic 模型。
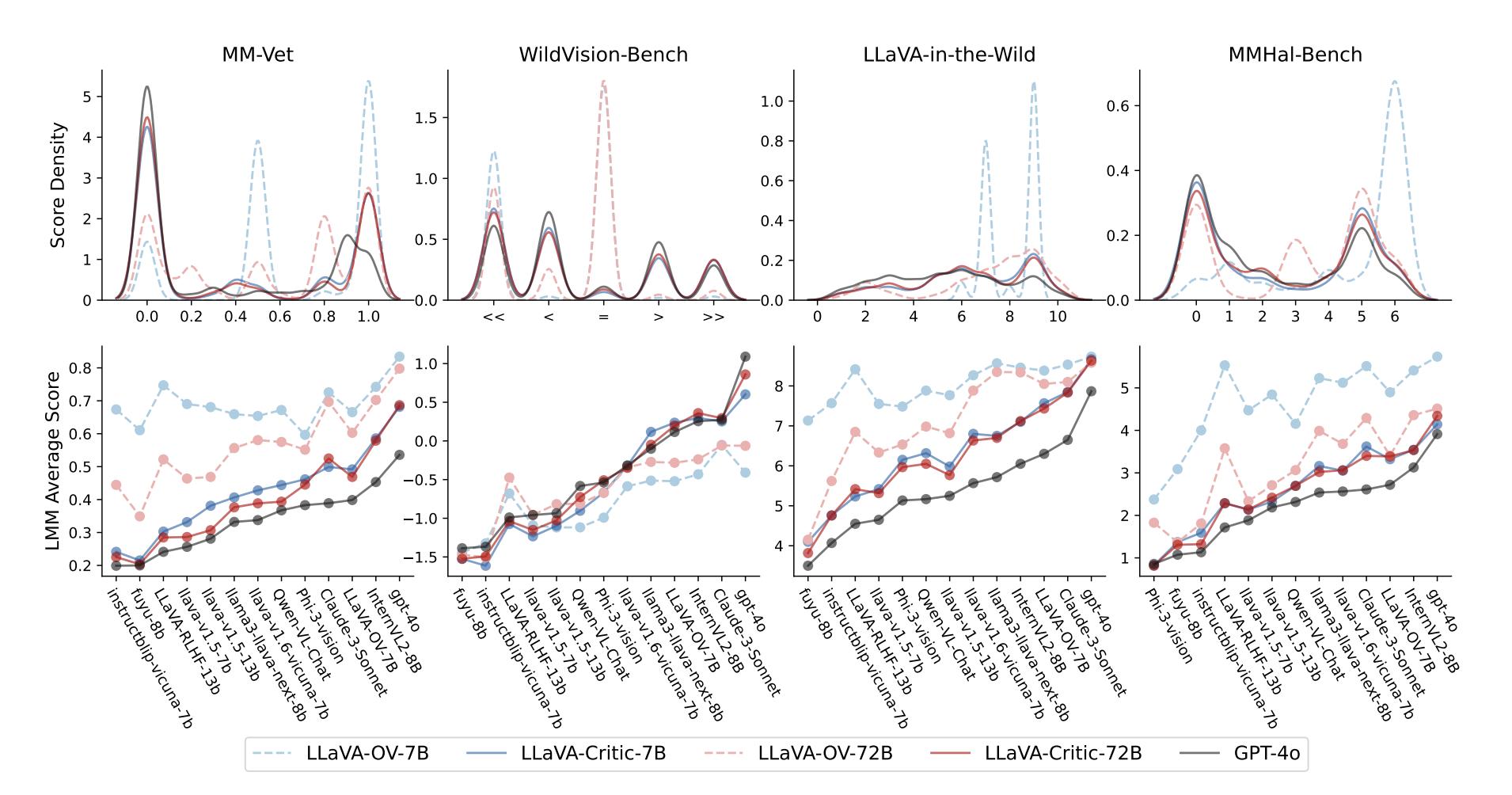
在评分的整体分布和对回复模型 (response model) 的排序层面上,LLaVA-Critic 均展现了与 GPT-4o 的一致性

在这个成对排序示例中,LLaVA-Critic 能够准确识别输入图像的内容(手写数字 「7」),并基于回复间的差异做出判断,给出了和人类评估者一致的排序,并提供了清晰的理由说明。后者(评分理由)对于构建可靠人工智能至关重要,它使 LLaVA-Critic 的评测过程更透明,评测结果更可信。
场景二:偏好学习(Preference Learning)
- 给定一个预训练 LMM 和一组图片 - 问题输入,首先让 LMM 对每一个图片 - 问题输入随机生成 K=5 个候选回复,由此构建出 Kx (K-1)=20 个成对回复。
- 接着,使用 LLaVA-Critic 对这 20 个回复对进行成对排序,选出最好和最坏的回复,形成成对的反馈数据集。
- 之后,使用这一数据集对于预训练 LMM 进行直接偏好优化(DPO)训练。在此基础上,渐进式迭代这一过程共计 M 轮,每次使用最新训练的模型生成候选回复,最终得到与 LLaVA-Critic 反馈对齐的模型。
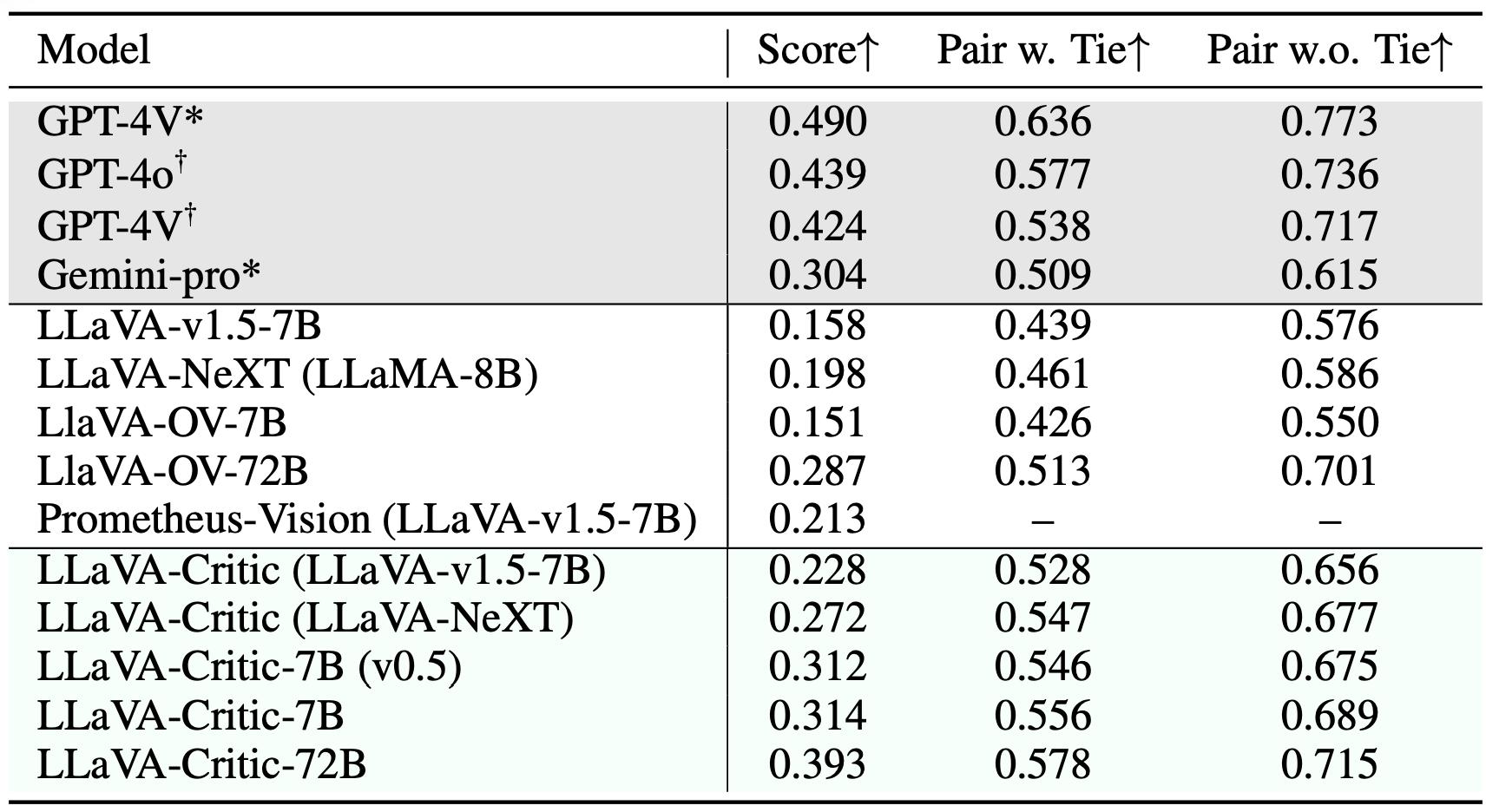
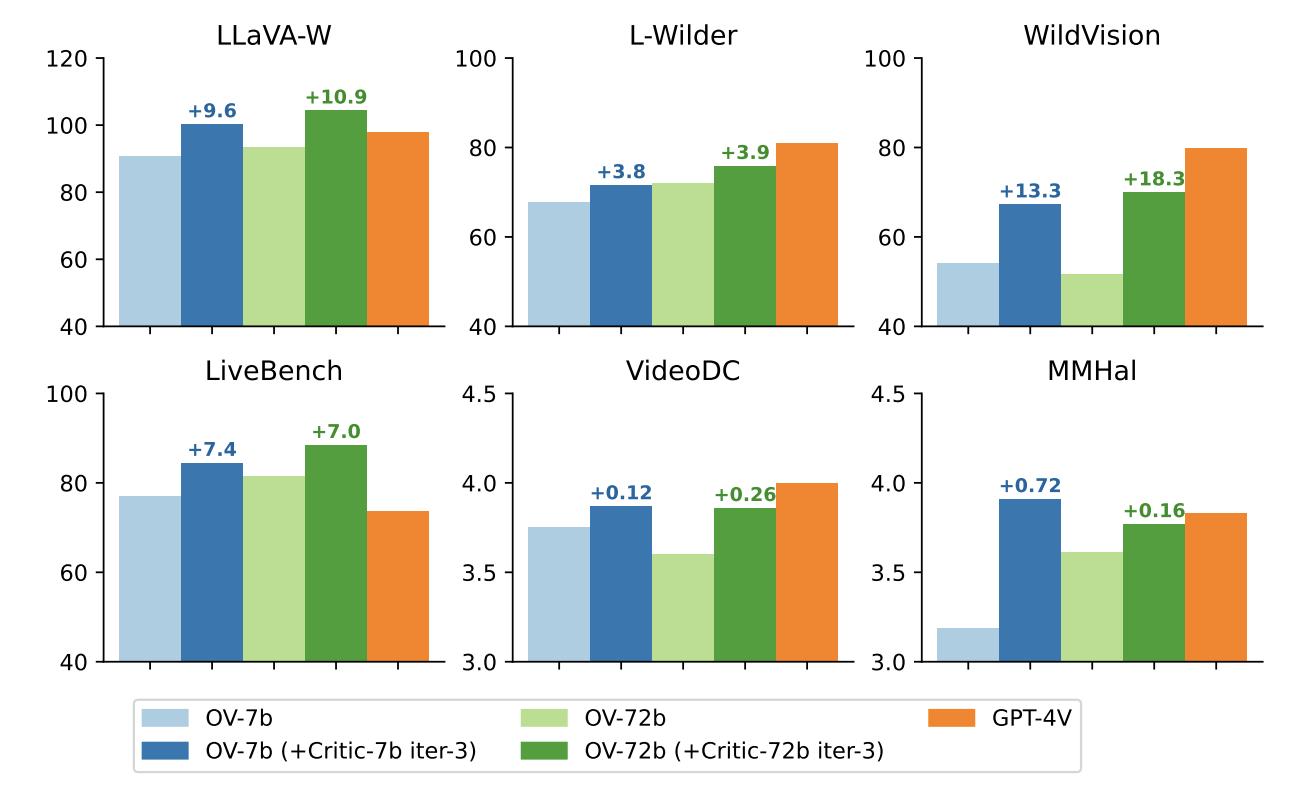
该团队采用 LLaVA-OneVision 作为初始 LMM,进行 3 轮 iterative DPO 训练,最终将训练后的模型命名为 LLaVA-OneVision-Chat。随后,他们在多个开放式问答评测基准上测试了最终模型的表现,以比较 LLaVA-Critic 和其他奖励模型的效果。如上表所示,无论是在 7B 还是 72B 基础模型上,LLaVA-Critic(AI 反馈)均超越了 LLaVA-RLHF (人类反馈),显著提升了基础模型在 6 个多模态开放式问答评测基准上的表现。
下方的柱状图进一步直观展示了 LLaVA-Critic 的反馈对 LLaVA-OneVision 模型在视觉问答性能上的提升效果。可见,LLaVA-Critic 作为一种提供有效奖励信号的可扩展方案,不仅减少了对昂贵人工反馈的依赖,还通过 AI 生成的反馈进一步优化了模型的偏好对齐效果。
结论
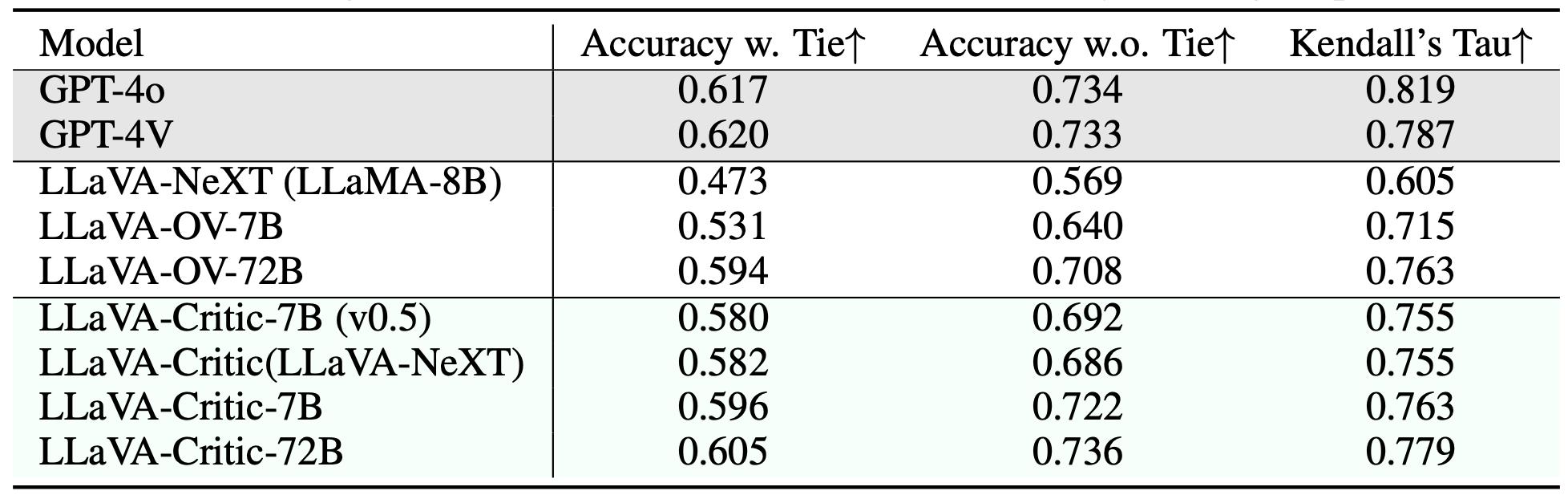
- 作为通用的评测器,LLaVA-Critic 能够为需要评测的模型回复提供单点评分和成对排序,这些评分和排序与人类和 GPT-4o 的偏好高度一致,为自动评测多模态大模型的开放式回复提供了一个可行的开源替代方案。
- 在偏好学习方面,LLaVA-Critic 提供的偏好信号能有效提升多模态大模型的视觉对话能力,甚至超越了基于人类反馈的 LLaVA-RLHF 奖励模型。