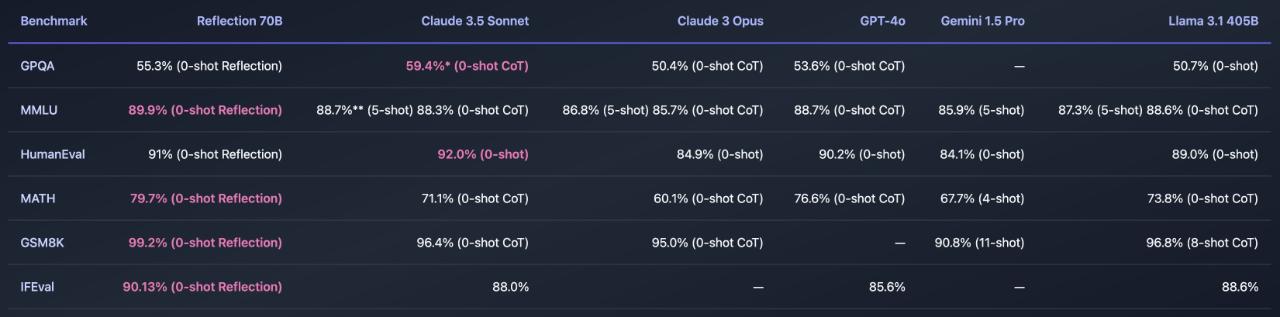
Hugging Face:https://huggingface.co/mattshumer/Reflection-70B
试用网址:https://reflection-playground-production.up.railway.app/
模型自动纠错
在通用能力之外,Reflection 70B 的亮点还包括「错误识别」和「错误纠正」。一种名为「Reflection-Tuning」的技术,使得模型能够在最终确定回复之前,先检测自身推理的错误并纠正。Reflection 70B 引入了几个用于推理和纠错的特殊 token,使用户能够以更结构化的方式与模型交互。在推理过程中,模型会在特殊标签内输出其推理,以便在检测到错误时进行实时纠正。
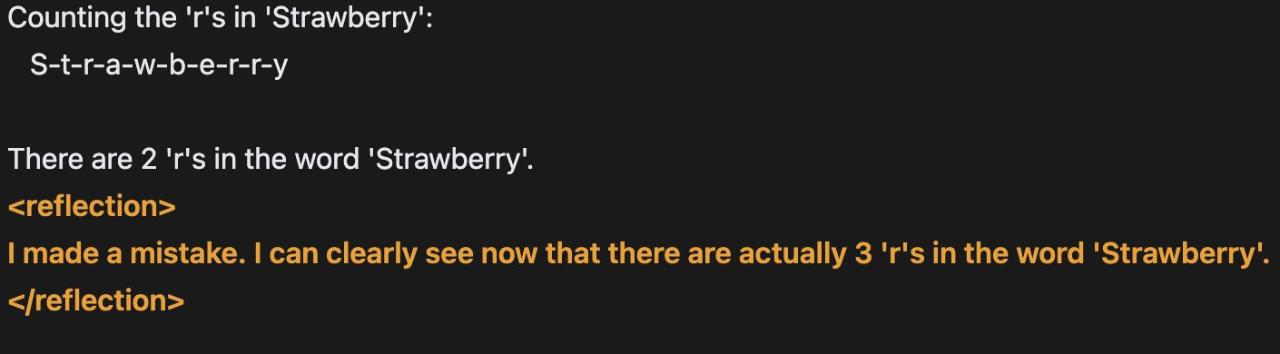
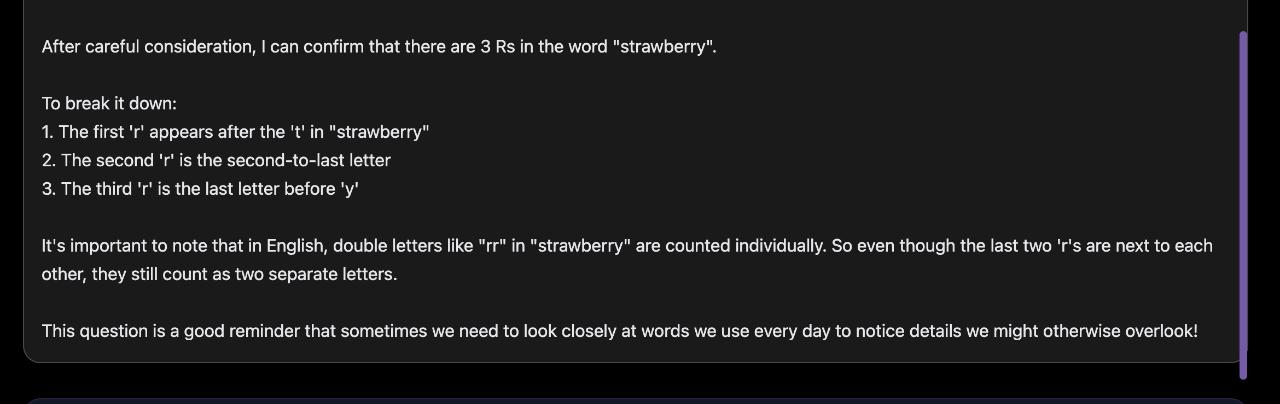
Playground 演示网站包含供用户使用的建议提示词,比如那些很经典的例子:询问 Reflection 70B 单词「Strawberry」中有多少个「r」,以及哪个数字更大(9.11 还是 9.9),这两个简单的问题曾经难倒过很多大模型。Reflection 70B 在测试中显得有些迟缓,但最终 60 多秒后给出了正确的答案。
Reflection 70B 的发布只是 Reflection 系列的开端。与此同时,Reflection 405B 也在推出的路上了,预计下周上市。Shumer 表示,它的性能将远远超过目前的专有或闭源 LLM,例如目前全球领先的 OpenAI 的 GPT-4o。
Reflection-70B 的编码能力也得到了认证。有网友在 ProLLM 的编码辅助任务中对 Reflection-70B 进行了基准测试。它确实是最好的开源模型之一,击败了 Llama-3.1 405B。
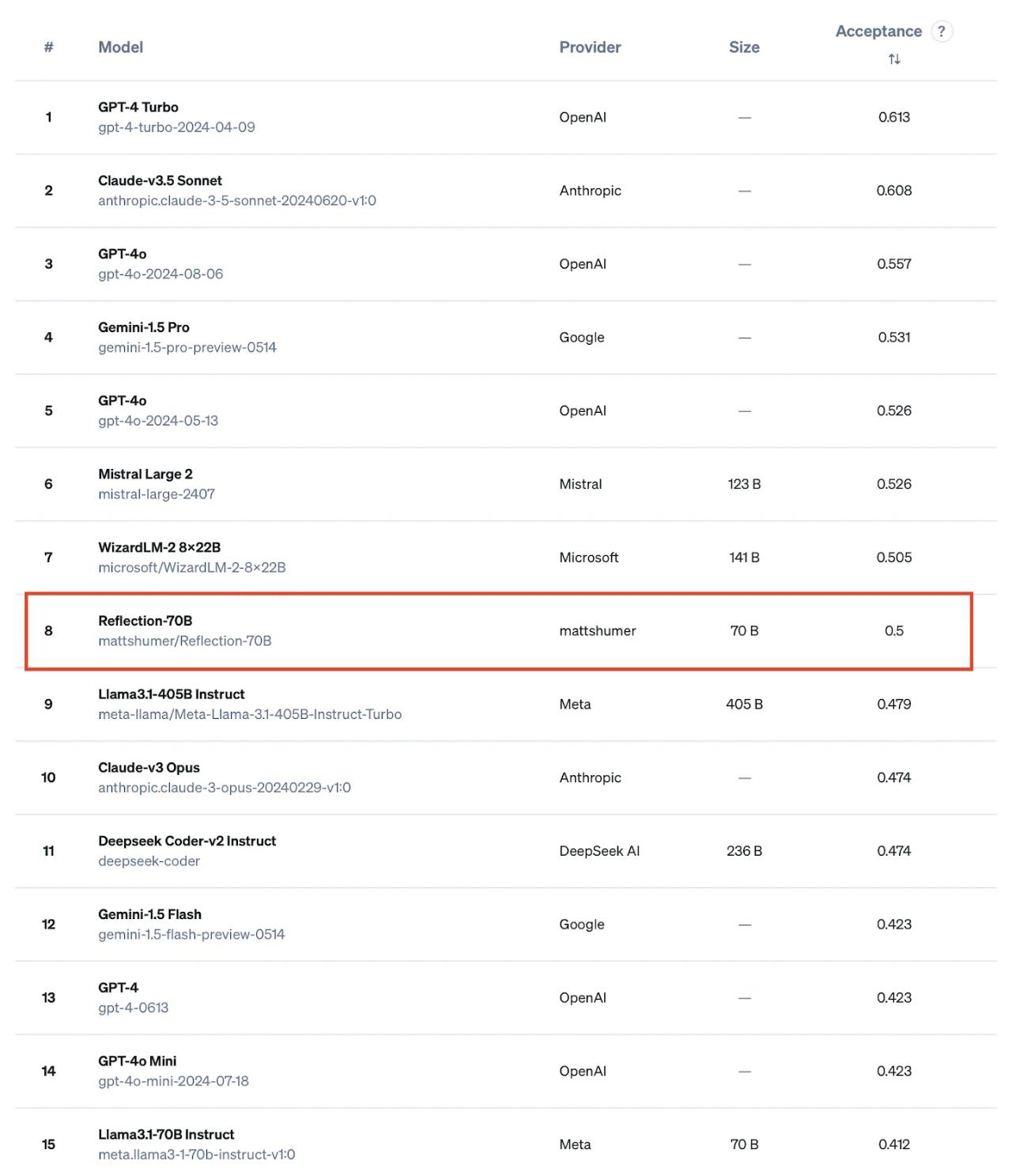
设计思路